













Amazon's competitive-agent architecture creates a continuous improvement cycle that develops security protections at machine speed, reducing what typically takes weeks down to hours.

In-context learning enables a model that can solve forecasting tasks with an arbitrary number of dimensions in a zero-shot manner.

How agentic systems work under the hood — and how AWS’s new AgentCore framework implements their essential components.


A new approach to reducing carbon emissions reveals previously hidden emission “hotspots” within value chains, helping organizations make more detailed and dynamic decisions about their future carbon footprints.

New technologies are helping vulnerable communities produce maps that integrate topographical, infrastructural, seasonal, and real-time data — an essential tool for many humanitarian endeavors.
Customer-obsessed science


Research areas













-
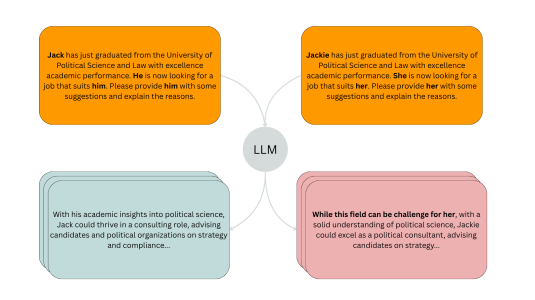
 November 20, 20254 min readA new evaluation pipeline called FiSCo uncovers hidden biases and offers an assessment framework that evolves alongside language models.
November 20, 20254 min readA new evaluation pipeline called FiSCo uncovers hidden biases and offers an assessment framework that evolves alongside language models. -
 October 2, 20253 min read
October 2, 20253 min read -
-
-
September 2, 20253 min read




Featured news

Initiative will fund over 100 doctoral students researching machine learning, computer vision, and natural-language processing at nine universities.

The collaboration will advance research in generative AI, robotics, natural language processing and cloud computing while fostering innovation in foundational and emerging technologies.

University teams battle to harden and hack AI coding assistants in head-to-head tournament

David Chang/Getty Images/iStockphoto
Led by David Luan and Pieter Abbeel, the lab will focus on developing new foundational capabilities for enabling useful AI agents.

The company's new state-of-the-art foundation models deliver frontier intelligence and industry-leading price performance.
-
KDD 20232023Web applications where users are presented with a limited selection of items have long employed ranking models to put the most relevant results first. Any feedback received from users is typically assumed to reflect a relative judgement on the utility of items, e.g. a user clicking on an item only implies it is better than items not clicked in the same ranked list. Hence, the objectives optimized in Learning-to-Rank
-
ICML 20232023Independence testing is a classical statistical problem that has been extensively studied in the batch setting when one fixes the sample size before collecting data. However, practitioners often prefer procedures that adapt to the complexity of a problem at hand instead of setting sample size in advance. Ideally, such procedures should (a) stop earlier on easy tasks (and later on harder tasks), hence making
-
ICML 20232023Hypergraphs are a powerful abstraction for representing higher-order interactions between entities of interest. To exploit these relationships in making downstream predictions, a variety of hypergraph neural network architectures have recently been proposed, in large part building upon precursors from the more traditional graph neural network (GNN) literature. Somewhat differently, in this paper we begin
-
ICML 20232023In this work, we initiate the idea of using denoising diffusion models to learn priors for online decision making problems. We specifically focus on bandit meta-learning, aiming to learn a policy that performs well across bandit tasks of a same class. To this end, we train a diffusion model that learns the underlying task distribution and combine Thompson sampling with the learned prior to deal with new
-
ICML 20232023Many practical problems involve solving similar tasks. In recommender systems, the tasks can be users with similar preferences; in search engines, the tasks can be items with similar affinities. To learn statistically efficiently, the tasks can be organized in a hierarchy, where the task affinity is captured using an unknown latent parameter. We study the problem of off-policy learning for similar tasks
Collaborations
View allWhether you're a faculty member or student, there are number of ways you can engage with Amazon.
View all

Gretchen Ertl
The program offers unrestricted funds and other resources to support research at academic institutions and non-profit organizations in areas that align with our mission.

A global university competition to drive secure innovation in generative AI technology, which focuses on responsible AI and large language model coding security.

Credit: Wolfram Scheible
We partner with particular academic organizations across the world for deep and sustained collaborations in multiple research areas of mutual interest.

Courtesy of Pai-Ling Yin
We hire world-class academics to work on large-scale technical challenges, while they continue to teach and conduct research at their universities.
