













A new approach to reducing carbon emissions reveals previously hidden emission “hotspots” within value chains, helping organizations make more detailed and dynamic decisions about their future carbon footprints.

How agentic systems work under the hood — and how AWS’s new AgentCore framework implements their essential components.

New technologies are helping vulnerable communities produce maps that integrate topographical, infrastructural, seasonal, and real-time data — an essential tool for many humanitarian endeavors.

In-context learning enables a model that can solve forecasting tasks with an arbitrary number of dimensions in a zero-shot manner.


"Kaputt" features 238,000+ images that advance the state of the art in detecting visual defects across complex retail applications.
Customer-obsessed science


Research areas













-
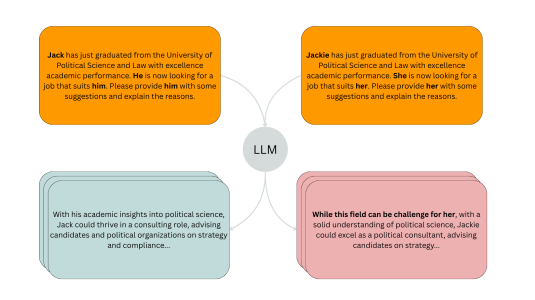
 November 20, 20254 min readA new evaluation pipeline called FiSCo uncovers hidden biases and offers an assessment framework that evolves alongside language models.
November 20, 20254 min readA new evaluation pipeline called FiSCo uncovers hidden biases and offers an assessment framework that evolves alongside language models. -

-
-
September 2, 20253 min read
-




Featured news

Initiative will fund over 100 doctoral students researching machine learning, computer vision, and natural-language processing at nine universities.

The collaboration will advance research in generative AI, robotics, natural language processing and cloud computing while fostering innovation in foundational and emerging technologies.

University teams battle to harden and hack AI coding assistants in head-to-head tournament

David Chang/Getty Images/iStockphoto
Led by David Luan and Pieter Abbeel, the lab will focus on developing new foundational capabilities for enabling useful AI agents.

The company's new state-of-the-art foundation models deliver frontier intelligence and industry-leading price performance.
-
2024Various types of learning rate (LR) schedulers are being used for training or fine tuning of Large Language Models today. In practice, several mid-flight changes are required in the LR schedule either manually, or with careful choices around warmup steps, peak LR, type of decay and restarts. To study this further, we consider the effect of switching the learning rate at a predetermined time during training
-
2024Large Language Models (LLMs) have shown impressive capabilities but also a concerning tendency to hallucinate. This paper presents REFCHECKER, a framework that introduces claim-triplets to represent claims in LLM responses, aiming to detect fine-grained hallucinations. In REFCHECKER, an extractor generates claim-triplets from a response, which are then evaluated by a checker against a reference. We delineate
-
ACM SoCC 20242024There has been a growing demand for making modern cloud-based data analytics systems cost-effective and easy to use. AI-powered intelligent resource scaling is one such effort, aiming at automating scaling decisions for serverless offerings like Amazon Redshift Serverless. The foundation of intelligent resource scaling lies in the ability to forecast query workloads and their resource consumption accurately
-
2024Machine unlearning is motivated by desire for data autonomy: a person can request to have their data’s influence removed from deployed models, and those models should be updated as if they were retrained without the person’s data. We show that, counter-intuitively, these updates expose individuals to high-accuracy reconstruction attacks which allow the attacker to recover their data in its entirety, even
-
NeurIPS 2024 Workshop on Table Representation Learning2024Machine learning (ML) models trained using Empirical Risk Minimization (ERM) often exhibit systematic errors on specific subpopulations of tabular data, known as error slices. Learning robust representation in the presence of error slices is challenging, especially in self-supervised settings during the feature reconstruction phase, due to high cardinality features and the complexity of constructing error
Collaborations
View allWhether you're a faculty member or student, there are number of ways you can engage with Amazon.
View all

Gretchen Ertl
The program offers unrestricted funds and other resources to support research at academic institutions and non-profit organizations in areas that align with our mission.

A global university competition to drive secure innovation in generative AI technology, which focuses on responsible AI and large language model coding security.

Credit: Wolfram Scheible
We partner with particular academic organizations across the world for deep and sustained collaborations in multiple research areas of mutual interest.

Courtesy of Pai-Ling Yin
We hire world-class academics to work on large-scale technical challenges, while they continue to teach and conduct research at their universities.
