













Amazon's competitive-agent architecture creates a continuous improvement cycle that develops security protections at machine speed, reducing what typically takes weeks down to hours.

In-context learning enables a model that can solve forecasting tasks with an arbitrary number of dimensions in a zero-shot manner.

How agentic systems work under the hood — and how AWS’s new AgentCore framework implements their essential components.


A new approach to reducing carbon emissions reveals previously hidden emission “hotspots” within value chains, helping organizations make more detailed and dynamic decisions about their future carbon footprints.

New technologies are helping vulnerable communities produce maps that integrate topographical, infrastructural, seasonal, and real-time data — an essential tool for many humanitarian endeavors.
Customer-obsessed science


Research areas













-
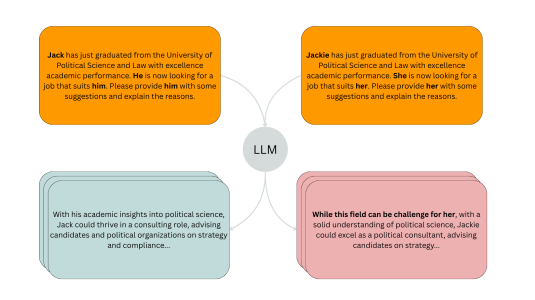
 November 20, 20254 min readA new evaluation pipeline called FiSCo uncovers hidden biases and offers an assessment framework that evolves alongside language models.
November 20, 20254 min readA new evaluation pipeline called FiSCo uncovers hidden biases and offers an assessment framework that evolves alongside language models. -
 October 2, 20253 min read
October 2, 20253 min read -
-
-
September 2, 20253 min read




Featured news

Initiative will fund over 100 doctoral students researching machine learning, computer vision, and natural-language processing at nine universities.

The collaboration will advance research in generative AI, robotics, natural language processing and cloud computing while fostering innovation in foundational and emerging technologies.

University teams battle to harden and hack AI coding assistants in head-to-head tournament

David Chang/Getty Images/iStockphoto
Led by David Luan and Pieter Abbeel, the lab will focus on developing new foundational capabilities for enabling useful AI agents.

The company's new state-of-the-art foundation models deliver frontier intelligence and industry-leading price performance.
-
ACL 2023 Workshop on SustaiNLP2023Prompting is a widely adopted technique for fine-tuning large language models. Recent research by Scao and Rush (2021) has demonstrated its effectiveness in improving few-shot learning performance compared to vanilla fine-tuning and also showed that prompting and vanilla fine tuning achieves similar performance in high data regime (∼> 2000 samples). This paper investigates the impact of imbalanced data
-
ICLR 2023 Workshop on Practical Machine Learning for Developing Countries (PML4DC)2023Language model based methods are powerful techniques for text classification. However, the models have several shortcomings. (1) It is difficult to integrate human knowledge such as keywords. (2) It needs a lot of resources to train the models. (3) It relied on large text data to pretrain. In this paper, we propose Semi-Supervised vMF Neural Topic Modeling (S2vNTM) to overcome these difficulties. S2vNTM
-
KDD 20232023Graph Neural Networks (GNNs) have achieved great success in modeling graph-structured data. However, recent works show that GNNs are vulnerable to adversarial attacks which can fool the GNN model to make desired predictions of the attacker. In addition, training data of GNNs can be leaked under membership inference attacks. This largely hinders the adoption of GNNs in high-stake domains such as e-commerce
-
ACL 2023 Workshop on Natural Language Reasoning and Structured Explanations2023Large language models have shown impressive abilities to reason over input text, however, they are prone to hallucinations. On the other hand, end-to-end knowledge graph question answering (KGQA) models output responses grounded in facts, but they still struggle with complex reasoning, such as comparison or ordinal questions. In this paper, we propose a new method for complex question answering where we
-
Interspeech 20232023Speech representations learned in a self-supervised fashion from massive unlabeled speech corpora have been adapted successfully toward several downstream tasks. However, such representations may be skewed toward canonical data characteristics of such corpora and perform poorly on atypical, nonnative accented speaker populations. With the state-of-the-art HuBERT model as a baseline, we propose and investigate
Collaborations
View allWhether you're a faculty member or student, there are number of ways you can engage with Amazon.
View all

Gretchen Ertl
The program offers unrestricted funds and other resources to support research at academic institutions and non-profit organizations in areas that align with our mission.

A global university competition to drive secure innovation in generative AI technology, which focuses on responsible AI and large language model coding security.

Credit: Wolfram Scheible
We partner with particular academic organizations across the world for deep and sustained collaborations in multiple research areas of mutual interest.

Courtesy of Pai-Ling Yin
We hire world-class academics to work on large-scale technical challenges, while they continue to teach and conduct research at their universities.
