













A new approach to reducing carbon emissions reveals previously hidden emission “hotspots” within value chains, helping organizations make more detailed and dynamic decisions about their future carbon footprints.

How agentic systems work under the hood — and how AWS’s new AgentCore framework implements their essential components.

New technologies are helping vulnerable communities produce maps that integrate topographical, infrastructural, seasonal, and real-time data — an essential tool for many humanitarian endeavors.

In-context learning enables a model that can solve forecasting tasks with an arbitrary number of dimensions in a zero-shot manner.


"Kaputt" features 238,000+ images that advance the state of the art in detecting visual defects across complex retail applications.
Customer-obsessed science


Research areas













-
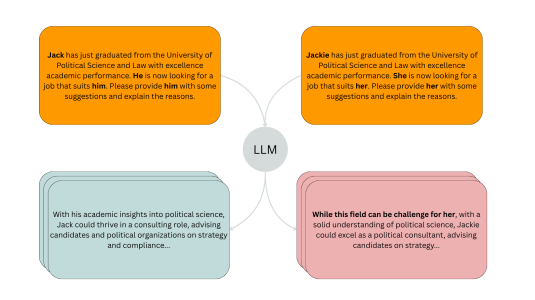
 November 20, 20254 min readA new evaluation pipeline called FiSCo uncovers hidden biases and offers an assessment framework that evolves alongside language models.
November 20, 20254 min readA new evaluation pipeline called FiSCo uncovers hidden biases and offers an assessment framework that evolves alongside language models. -

-
-
September 2, 20253 min read
-




Featured news

Initiative will fund over 100 doctoral students researching machine learning, computer vision, and natural-language processing at nine universities.

The collaboration will advance research in generative AI, robotics, natural language processing and cloud computing while fostering innovation in foundational and emerging technologies.

University teams battle to harden and hack AI coding assistants in head-to-head tournament

David Chang/Getty Images/iStockphoto
Led by David Luan and Pieter Abbeel, the lab will focus on developing new foundational capabilities for enabling useful AI agents.

The company's new state-of-the-art foundation models deliver frontier intelligence and industry-leading price performance.
-
SIGIR 2024 Workshop on eCommerce2024Vision-language transformer models play a pivotal role in e-commerce product search. When using product description (e.g. product title) and product image pairs to train such models, there are often non-visual-descriptive text attributes in the product description, which makes the visual textual alignment challenging. We introduce MultiModal Learning with online Token Pruning (MML-TP). MML-TP leverages
-
2024Existing work in scientific machine learning (SciML) has shown that data-driven learning of solution operators can provide a fast approximate alternative to classical numerical partial differential equation (PDE) solvers. Of these, Neural Operators (NOs) have emerged as particularly promising. We observe that several uncertainty quantification (UQ) methods for NOs fail for test inputs that are even moderately
-
Transactions on Machine Learning Research2024Recent breakthroughs in large language modeling have facilitated rigorous exploration of their application in diverse tasks related to tabular data modeling, such as prediction, tabular data synthesis, question answering, and table understanding. Each task presents unique challenges and opportunities. However, there is currently a lack of comprehensive review that summarizes and compares the key techniques
-
Reasoning and planning with large language models in code development (survey for KDD 2024 tutorial)2024Large Language Models (LLMs) are revolutionizing the field of code development by leveraging their deep understanding of code patterns, syntax, and semantics to assist developers in various tasks, from code generation and testing to code understanding and documentation. In this survey, accompanying our proposed lecture-style tutorial for KDD 2024, we explore the multifaceted impact of LLMs on code development
-
2024Large Language Models (LLMs) tend to be unreliable in the factuality of their answers. To address this problem, NLP researchers have proposed a range of techniques to estimate LLM’s confidence over facts. However, due to the lack of a systematic comparison, it is not clear how the different methods compare to one another. To fill this gap, we present a survey and empirical comparison of estimators of factual
Collaborations
View allWhether you're a faculty member or student, there are number of ways you can engage with Amazon.
View all

Gretchen Ertl
The program offers unrestricted funds and other resources to support research at academic institutions and non-profit organizations in areas that align with our mission.

A global university competition to drive secure innovation in generative AI technology, which focuses on responsible AI and large language model coding security.

Credit: Wolfram Scheible
We partner with particular academic organizations across the world for deep and sustained collaborations in multiple research areas of mutual interest.

Courtesy of Pai-Ling Yin
We hire world-class academics to work on large-scale technical challenges, while they continue to teach and conduct research at their universities.
