













Amazon's competitive-agent architecture creates a continuous improvement cycle that develops security protections at machine speed, reducing what typically takes weeks down to hours.

In-context learning enables a model that can solve forecasting tasks with an arbitrary number of dimensions in a zero-shot manner.

How agentic systems work under the hood — and how AWS’s new AgentCore framework implements their essential components.


A new approach to reducing carbon emissions reveals previously hidden emission “hotspots” within value chains, helping organizations make more detailed and dynamic decisions about their future carbon footprints.

New technologies are helping vulnerable communities produce maps that integrate topographical, infrastructural, seasonal, and real-time data — an essential tool for many humanitarian endeavors.
Customer-obsessed science


Research areas













-
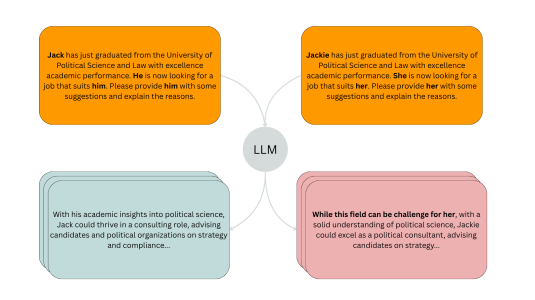
 November 20, 20254 min readA new evaluation pipeline called FiSCo uncovers hidden biases and offers an assessment framework that evolves alongside language models.
November 20, 20254 min readA new evaluation pipeline called FiSCo uncovers hidden biases and offers an assessment framework that evolves alongside language models. -
 October 2, 20253 min read
October 2, 20253 min read -
-
-
September 2, 20253 min read




Featured news

Initiative will fund over 100 doctoral students researching machine learning, computer vision, and natural-language processing at nine universities.

The collaboration will advance research in generative AI, robotics, natural language processing and cloud computing while fostering innovation in foundational and emerging technologies.

University teams battle to harden and hack AI coding assistants in head-to-head tournament

David Chang/Getty Images/iStockphoto
Led by David Luan and Pieter Abbeel, the lab will focus on developing new foundational capabilities for enabling useful AI agents.

The company's new state-of-the-art foundation models deliver frontier intelligence and industry-leading price performance.
-
Mitigating the burden of redundant datasets via batch-wise unique samples and frequency-aware lossesACL 20232023Datasets used to train deep learning models in industrial settings often exhibit skewed distributions with some samples repeated a large number of times. This paper presents a simple yet effective solution to reduce the increased burden of repeated computation on redundant datasets. Our approach eliminates duplicates at the batch level, without altering the data distribution observed by the model, making
-
ICRA Workshop on Robot Execution Failures and Failure Management Strategies2023This paper describes how to define and execute tasks that depend on localization for their success. Real-world robotic systems that perform precise work at endpoints generally have tasks that fail if a robot’s localization error is above the task requirement. However, most systems for considering localization error are task-agnostic. We distinguish between business-case-required work tasks and localization
-
The Web Conference Workshop on Interactive and Scalable Information Retrieval Methods for eCommerce (ISIR-eCom)2023Product search for online shopping should be season-aware, i.e., presenting seasonally relevant products to customers. In this paper, we propose a simple yet effective solution to improve seasonal relevance in product search by incorporating seasonality into language models for semantic matching. We first identify seasonal queries and products by analyzing implicit seasonal contexts through time-series
-
SIGIR 20232023In order to determine the relevance of a given item to a query, most modern search ranking systems make use of features which aggregate prior user behavior for that item and query (e.g. click rate). For practical reasons, when running A/B tests on ranking systems, these features are generally shared between all treatments. For the most common experiment designs, which randomize traffic by user or by session
-
SIGIR 20232023Online evaluation techniques are widely adopted by industrial search engines to determine which ranking models perform better under a certain business metric. However, online evaluation can only evaluate a small number of rankers and people resort to offline evaluation to select rankers that are likely to yield good online performance. To use offline metrics for effective model selection, a major challenge
Collaborations
View allWhether you're a faculty member or student, there are number of ways you can engage with Amazon.
View all

Gretchen Ertl
The program offers unrestricted funds and other resources to support research at academic institutions and non-profit organizations in areas that align with our mission.

A global university competition to drive secure innovation in generative AI technology, which focuses on responsible AI and large language model coding security.

Credit: Wolfram Scheible
We partner with particular academic organizations across the world for deep and sustained collaborations in multiple research areas of mutual interest.

Courtesy of Pai-Ling Yin
We hire world-class academics to work on large-scale technical challenges, while they continue to teach and conduct research at their universities.
