













A new approach to reducing carbon emissions reveals previously hidden emission “hotspots” within value chains, helping organizations make more detailed and dynamic decisions about their future carbon footprints.

How agentic systems work under the hood — and how AWS’s new AgentCore framework implements their essential components.

New technologies are helping vulnerable communities produce maps that integrate topographical, infrastructural, seasonal, and real-time data — an essential tool for many humanitarian endeavors.

In-context learning enables a model that can solve forecasting tasks with an arbitrary number of dimensions in a zero-shot manner.


"Kaputt" features 238,000+ images that advance the state of the art in detecting visual defects across complex retail applications.
Customer-obsessed science


Research areas













-
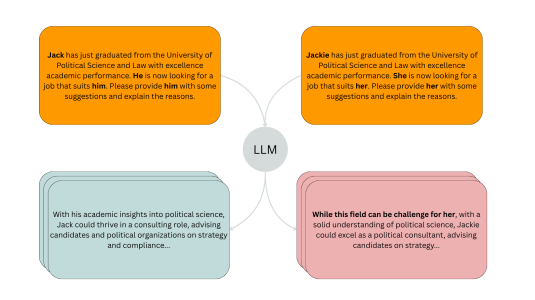
 November 20, 20254 min readA new evaluation pipeline called FiSCo uncovers hidden biases and offers an assessment framework that evolves alongside language models.
November 20, 20254 min readA new evaluation pipeline called FiSCo uncovers hidden biases and offers an assessment framework that evolves alongside language models. -

-
-
September 2, 20253 min read
-




Featured news

Initiative will fund over 100 doctoral students researching machine learning, computer vision, and natural-language processing at nine universities.

The collaboration will advance research in generative AI, robotics, natural language processing and cloud computing while fostering innovation in foundational and emerging technologies.

University teams battle to harden and hack AI coding assistants in head-to-head tournament

David Chang/Getty Images/iStockphoto
Led by David Luan and Pieter Abbeel, the lab will focus on developing new foundational capabilities for enabling useful AI agents.

The company's new state-of-the-art foundation models deliver frontier intelligence and industry-leading price performance.
-
2024Large self-supervised models have excelled in various speech processing tasks, but their deployment on resource-limited devices is often impractical due to their substantial memory footprint. Previous studies have demonstrated the effectiveness of self-supervised pre-training for keyword spotting, even with constrained model capacity. In our pursuit of maintaining high performance while minimizing the model
-
ECIR 20242024Negative sample selection has been shown to have a crucial effect on the training procedure of dense retrieval systems. Nevertheless, most existing negative selection methods end by randomly choosing from some pool of samples. This calls for a better sampling solution. We define desired requirements for negative sample selection; the samples chosen should be informative, to advance the learning process,
-
ACM Conference on Intelligent User Interfaces (ACM IUI) 20242024Object detection tasks are central to the development of datasets and algorithms in computer vision and machine learning. Despite its centrality, object detection remains tedious and time-consuming due to the inherent interactions that are often associated with drawing precise annotations. In this paper, we introduce Snapper, an interactive and intelligent annotation tool that intercepts bounding box annotations
-
AAAI 20242024Inferring the 3D structure of a non-rigid dynamic scene from a single moving camera is an under-constrained problem. Inspired by the remarkable progress of neural radiance fields (NeRFs) in photo-realistic novel view synthesis of static scenes, it has also been extended to dynamic settings. Such methods heavily rely on implicit neural priors to regularize the problem. In this work, we take a step back and
-
INFORMS Journal on Data Science2024Accurate credit ratings are an essential ingredient in the decision-making process for investors, rating agencies, bond portfolio managers, bankers, and policy makers, as well as an important input for risk management and regulation. Credit ratings are traditionally generated from models that use financial statement data and market data, which are tabular (numeric and categorical). Using machine learning
Collaborations
View allWhether you're a faculty member or student, there are number of ways you can engage with Amazon.
View all

Gretchen Ertl
The program offers unrestricted funds and other resources to support research at academic institutions and non-profit organizations in areas that align with our mission.

A global university competition to drive secure innovation in generative AI technology, which focuses on responsible AI and large language model coding security.

Credit: Wolfram Scheible
We partner with particular academic organizations across the world for deep and sustained collaborations in multiple research areas of mutual interest.

Courtesy of Pai-Ling Yin
We hire world-class academics to work on large-scale technical challenges, while they continue to teach and conduct research at their universities.
