













A new approach to reducing carbon emissions reveals previously hidden emission “hotspots” within value chains, helping organizations make more detailed and dynamic decisions about their future carbon footprints.

How agentic systems work under the hood — and how AWS’s new AgentCore framework implements their essential components.

New technologies are helping vulnerable communities produce maps that integrate topographical, infrastructural, seasonal, and real-time data — an essential tool for many humanitarian endeavors.

In-context learning enables a model that can solve forecasting tasks with an arbitrary number of dimensions in a zero-shot manner.


"Kaputt" features 238,000+ images that advance the state of the art in detecting visual defects across complex retail applications.
Customer-obsessed science


Research areas













-
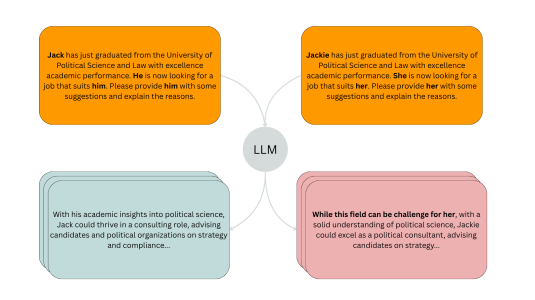
 November 20, 20254 min readA new evaluation pipeline called FiSCo uncovers hidden biases and offers an assessment framework that evolves alongside language models.
November 20, 20254 min readA new evaluation pipeline called FiSCo uncovers hidden biases and offers an assessment framework that evolves alongside language models. -

-
-
September 2, 20253 min read
-




Featured news

Initiative will fund over 100 doctoral students researching machine learning, computer vision, and natural-language processing at nine universities.

The collaboration will advance research in generative AI, robotics, natural language processing and cloud computing while fostering innovation in foundational and emerging technologies.

University teams battle to harden and hack AI coding assistants in head-to-head tournament

David Chang/Getty Images/iStockphoto
Led by David Luan and Pieter Abbeel, the lab will focus on developing new foundational capabilities for enabling useful AI agents.

The company's new state-of-the-art foundation models deliver frontier intelligence and industry-leading price performance.
-
2024Existing dense retrieval systems utilize the same model architecture for encoding both the passages and the queries, even though queries are much shorter and simpler than passages. This leads to high latency of the query encoding, which is performed online and therefore might impact user experience. We show that combining a standard large passage encoder with a small efficient query encoder can provide
-
2024We investigate the problem of synthesizing relevant visual imagery from generic long-form text, leveraging Large Language Models (LLMs) and Text-to-Image Models (TIMs). Current Text-to-Image models require short prompts that describe the image content and style explicitly. Unlike image prompts, generation of images from general long-form text requires the image synthesis system to derive the visual content
-
2024In deep metric learning for visual recognition, the calibration of distance thresholds is crucial for achieving desired model performance in the true positive rates (TPR) or true negative rates (TNR). However, calibrating this threshold presents challenges in open-world scenarios, where the test classes can be entirely disjoint from those encountered during training. We define the problem of finding distance
-
2024Single document news summarization has seen substantial progress on faithfulness in recent years, driven by research on the evaluation of factual consistency, or hallucinations. We ask whether these advances carry over to other text summarization domains. We propose a new evaluation benchmark on topic-focused dialogue summarization, generated by LLMs of varying sizes. We provide binary sentence-level human
-
2024Pre-trained masked language models, such as BERT, perform strongly on a wide variety of NLP tasks and have become ubiquitous in recent years. The typical way to use such models is to fine-tune them on downstream data. In this work, we aim to study how the difference in domains between the pre-trained model and the task effects its final performance. We first devise a simple mechanism to quantify the domain
Collaborations
View allWhether you're a faculty member or student, there are number of ways you can engage with Amazon.
View all

Gretchen Ertl
The program offers unrestricted funds and other resources to support research at academic institutions and non-profit organizations in areas that align with our mission.

A global university competition to drive secure innovation in generative AI technology, which focuses on responsible AI and large language model coding security.

Credit: Wolfram Scheible
We partner with particular academic organizations across the world for deep and sustained collaborations in multiple research areas of mutual interest.

Courtesy of Pai-Ling Yin
We hire world-class academics to work on large-scale technical challenges, while they continue to teach and conduct research at their universities.
