












Amazon vice president and distinguished engineer Marc Brooker explains how agentic systems work under the hood — and how AWS’s new AgentCore framework implements their essential components.


Initiative will fund over 100 doctoral students researching machine learning, computer vision, and natural-language processing at nine universities.

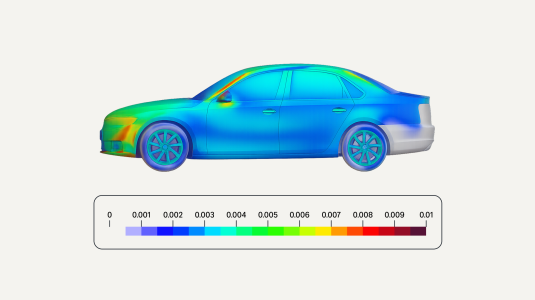
In-context learning enables a model that can solve forecasting tasks with an arbitrary number of dimensions in a zero-shot manner.

New technologies are helping vulnerable communities produce maps that integrate topographical, infrastructural, seasonal, and real-time data — an essential tool for many humanitarian endeavors.


A new dataset with over 238,000 images challenges and advances the state of the art in visual defect detection for complex retail applications.
Customer-obsessed science


Research areas













-
 September 26, 2025To transform scientific domains, foundation models will require physical-constraint satisfaction, uncertainty quantification, and specialized forecasting techniques that overcome data scarcity while maintaining scientific rigor.
September 26, 2025To transform scientific domains, foundation models will require physical-constraint satisfaction, uncertainty quantification, and specialized forecasting techniques that overcome data scarcity while maintaining scientific rigor. -





Featured news

The collaboration will advance research in generative AI, robotics, natural language processing and cloud computing while fostering innovation in foundational and emerging technologies.

Amazon Research Awards have opened their Fall call for proposals, which closes November 5, 2025.

University teams battle to harden and hack AI coding assistants in head-to-head tournament

David Chang/Getty Images/iStockphoto
Led by David Luan and Pieter Abbeel, the lab will focus on developing new foundational capabilities for enabling useful AI agents.

The company's new state-of-the-art foundation models deliver frontier intelligence and industry-leading price performance.
-
2025In this work, we introduce long-video masked-embedding autoencoders (LV-MAE), a self-supervised learning framework for long video representation. Our approach treats short- and long-span dependencies as two separate tasks. Such decoupling allows for a more intuitive video processing where short-span spatiotemporal primitives are first encoded and are then used to capture long-range dependencies across consecutive
-
2025Large Language Models (LLMs) often suffer from mode collapse, repeatedly generating the same few completions even when many valid answers exist, limiting their diversity across a wide range of tasks. We introduce Group-Aware Policy Optimization (GAPO), a simple extension of the recent and popular Group Relative Policy Optimization (GRPO) that computes rewards over the group as a whole. GAPO enables learning
-
2025Large Language Models (LLMs) often generate responses with inherent biases, undermining their reliability in real-world applications. Existing evaluation methods often overlook biases in long-form responses and the intrinsic variability of LLM outputs. To address these challenges, we pro-pose FiSCo (Fine-grained Semantic Comparison), a novel statistical frame-work to evaluate group-level fairness in LLMs
-
2025Safety alignment approaches in large language models (LLMs) often lead to the over-refusal of benign queries, significantly diminishing their utility in sensitive scenarios. To address this challenge, we introduce FalseReject, a comprehensive resource containing 16k seemingly toxic queries accompanied by structured responses across 44 safety-related categories. We propose a graph-informed adversarial multi-agent
-
2025The proliferation of multimodal Large Language Models has significantly advanced the ability to analyze and understand complex data inputs from different modalities. However, the processing of long documents remains under-explored, largely due to a lack of suitable benchmarks. To address this, we introduce Document Haystack12 , a comprehensive benchmark designed to evaluate the performance of Vision Language
Conferences
Collaborations
View allWhether you're a faculty member or student, there are number of ways you can engage with Amazon.
View all

Gretchen Ertl
The program offers unrestricted funds and other resources to support research at academic institutions and non-profit organizations in areas that align with our mission.

A global university competition to drive secure innovation in generative AI technology, which focuses on responsible AI and large language model coding security.

Credit: Wolfram Scheible
We partner with particular academic organizations across the world for deep and sustained collaborations in multiple research areas of mutual interest.

Courtesy of Pai-Ling Yin
We hire world-class academics to work on large-scale technical challenges, while they continue to teach and conduct research at their universities.
