













Amazon's competitive-agent architecture creates a continuous improvement cycle that develops security protections at machine speed, reducing what typically takes weeks down to hours.

In-context learning enables a model that can solve forecasting tasks with an arbitrary number of dimensions in a zero-shot manner.

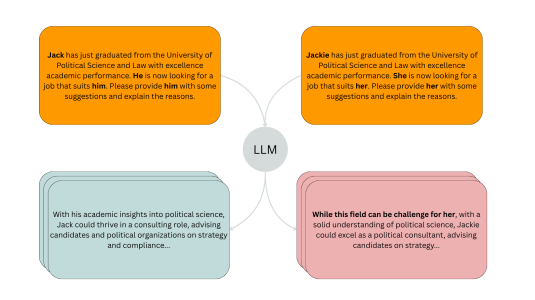
How agentic systems work under the hood — and how AWS’s new AgentCore framework implements their essential components.


A new approach to reducing carbon emissions reveals previously hidden emission “hotspots” within value chains, helping organizations make more detailed and dynamic decisions about their future carbon footprints.

New technologies are helping vulnerable communities produce maps that integrate topographical, infrastructural, seasonal, and real-time data — an essential tool for many humanitarian endeavors.
Customer-obsessed science


Research areas













-
 November 20, 20254 min readA new evaluation pipeline called FiSCo uncovers hidden biases and offers an assessment framework that evolves alongside language models.
November 20, 20254 min readA new evaluation pipeline called FiSCo uncovers hidden biases and offers an assessment framework that evolves alongside language models. -
 October 2, 20253 min read
October 2, 20253 min read -
-
-
September 2, 20253 min read




Featured news

Initiative will fund over 100 doctoral students researching machine learning, computer vision, and natural-language processing at nine universities.

The collaboration will advance research in generative AI, robotics, natural language processing and cloud computing while fostering innovation in foundational and emerging technologies.

University teams battle to harden and hack AI coding assistants in head-to-head tournament

David Chang/Getty Images/iStockphoto
Led by David Luan and Pieter Abbeel, the lab will focus on developing new foundational capabilities for enabling useful AI agents.

The company's new state-of-the-art foundation models deliver frontier intelligence and industry-leading price performance.
-
Interspeech 20232023Conformer is an extension of transformer-based neural ASR models whose fundamental component is the self-attention module. In this paper, we show that we can remove the self-attention module from Conformer and achieve the same or even better recognition performance for utterances whose length is up to around 10 seconds. This is particularly important for streaming interactive voice assistants as input is
-
Interspeech 20232023Contextual biasing (CB) is an effective approach for contextualising hidden features of neural transducer ASR models to improve rare word recognition. CB relies on relatively large quantities of relevant human annotated natural speech during training, limiting its effectiveness in low-resource scenarios. In this work, we propose a novel approach that reduces the reliance on real speech by using synthesised
-
Interspeech 20232023Voice assistant accessibility is generally overlooked as today’s spoken dialogue systems are trained on huge corpora to help them understand the ‘average’ user. This raises frustrating barriers for certain user groups as their speech shifts from the average. People with dementia pause more frequently mid-sentence for example, and people with hearing impairments may mispronounce words learned post-diagnosis
-
KDD 20232023Graph neural networks (GNNs) have shown high potential for a variety of real-world, challenging applications, but one of the major obstacles in GNN research is the lack of large-scale flexible datasets. Most existing public datasets for GNNs are relatively small, which limits the ability of GNNs to generalize to unseen data. The few existing large-scale graph datasets provide very limited labeled data.
-
Interspeech 20232023Large self-supervised models are effective feature extractors, but their application is challenging under on-device budget constraints and biased dataset collection, especially in keyword spotting. To address this, we proposed a knowledge distillation-based self-supervised speech representation learning (S3RL) architecture for on-device keyword spotting. Our approach used a teacher-student framework to
Collaborations
View allWhether you're a faculty member or student, there are number of ways you can engage with Amazon.
View all

Gretchen Ertl
The program offers unrestricted funds and other resources to support research at academic institutions and non-profit organizations in areas that align with our mission.

A global university competition to drive secure innovation in generative AI technology, which focuses on responsible AI and large language model coding security.

Credit: Wolfram Scheible
We partner with particular academic organizations across the world for deep and sustained collaborations in multiple research areas of mutual interest.

Courtesy of Pai-Ling Yin
We hire world-class academics to work on large-scale technical challenges, while they continue to teach and conduct research at their universities.
