













A new approach to reducing carbon emissions reveals previously hidden emission “hotspots” within value chains, helping organizations make more detailed and dynamic decisions about their future carbon footprints.

How agentic systems work under the hood — and how AWS’s new AgentCore framework implements their essential components.

New technologies are helping vulnerable communities produce maps that integrate topographical, infrastructural, seasonal, and real-time data — an essential tool for many humanitarian endeavors.

In-context learning enables a model that can solve forecasting tasks with an arbitrary number of dimensions in a zero-shot manner.


"Kaputt" features 238,000+ images that advance the state of the art in detecting visual defects across complex retail applications.
Customer-obsessed science


Research areas













-
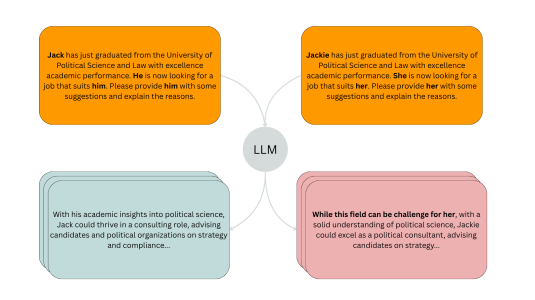
 November 20, 20254 min readA new evaluation pipeline called FiSCo uncovers hidden biases and offers an assessment framework that evolves alongside language models.
November 20, 20254 min readA new evaluation pipeline called FiSCo uncovers hidden biases and offers an assessment framework that evolves alongside language models. -

-
-
September 2, 20253 min read
-




Featured news

Initiative will fund over 100 doctoral students researching machine learning, computer vision, and natural-language processing at nine universities.

The collaboration will advance research in generative AI, robotics, natural language processing and cloud computing while fostering innovation in foundational and emerging technologies.

University teams battle to harden and hack AI coding assistants in head-to-head tournament

David Chang/Getty Images/iStockphoto
Led by David Luan and Pieter Abbeel, the lab will focus on developing new foundational capabilities for enabling useful AI agents.

The company's new state-of-the-art foundation models deliver frontier intelligence and industry-leading price performance.
-
2024Foundation models (FMs) learn from large volumes of unlabeled data to demonstrate superior performance across a wide range of tasks. However, FMs developed for biomedical domains have largely remained unimodal, i.e., independently trained and used for tasks on protein sequences alone, small-molecule structures alone, or clinical data alone. To overcome this limitation, we present BioBRIDGE, a parameter-efficient
-
EACL 2024 Workshop on Linguistic Annotation2024Recent developments in active learning algorithms for NLP tasks show promising results in terms of reducing labelling complexity. In this paper we extend this effort to imbalanced datasets; we bridge between the active learning approach of obtaining diverse and informative examples, and the heuristic of class balancing used in imbalanced datasets. We develop a novel tune-free weighting technique that can
-
ICASSP 2024 Workshop on Self-supervision in Audio, Speech and Beyond2024Voice conversion (VC) systems are widely used for several applications, from speaker anonymisation to personalised speech synthesis. Supervised approaches learn a mapping between different speakers using parallel data, which is expensive to produce. Un-supervised approaches are typically trained to reconstruct the in-put signal, which is composed of the content and the speaker in-formation. Disentangling
-
2024Cross-triggering is a critical problem for applications of audio event detection (AED), particularly in low-resource settings. However, not much attention (if not none) has been paid to this problem in the AED research community. In this work, we tackle this problem via a regularization approach. We propose a regularizer, namely mutual exclusivity regularizer, that is able to enforce pairwise exclusivity
-
arXiv2024We introduce a text-to-speech (TTS) model called BASE TTS, which stands for Big Adaptive Streamable TTS with Emergent abilities. BASE TTS is the largest TTS model to-date, trained on 100K hours of public domain speech data, achieving a new state-of-the-art in speech naturalness. It deploys a 1-billion- parameter autoregressive Transformer that converts raw texts into discrete codes ("speechcodes") followed
Collaborations
View allWhether you're a faculty member or student, there are number of ways you can engage with Amazon.
View all

Gretchen Ertl
The program offers unrestricted funds and other resources to support research at academic institutions and non-profit organizations in areas that align with our mission.

A global university competition to drive secure innovation in generative AI technology, which focuses on responsible AI and large language model coding security.

Credit: Wolfram Scheible
We partner with particular academic organizations across the world for deep and sustained collaborations in multiple research areas of mutual interest.

Courtesy of Pai-Ling Yin
We hire world-class academics to work on large-scale technical challenges, while they continue to teach and conduct research at their universities.
