













A new approach to reducing carbon emissions reveals previously hidden emission “hotspots” within value chains, helping organizations make more detailed and dynamic decisions about their future carbon footprints.

How agentic systems work under the hood — and how AWS’s new AgentCore framework implements their essential components.

New technologies are helping vulnerable communities produce maps that integrate topographical, infrastructural, seasonal, and real-time data — an essential tool for many humanitarian endeavors.

In-context learning enables a model that can solve forecasting tasks with an arbitrary number of dimensions in a zero-shot manner.


"Kaputt" features 238,000+ images that advance the state of the art in detecting visual defects across complex retail applications.
Customer-obsessed science


Research areas













-
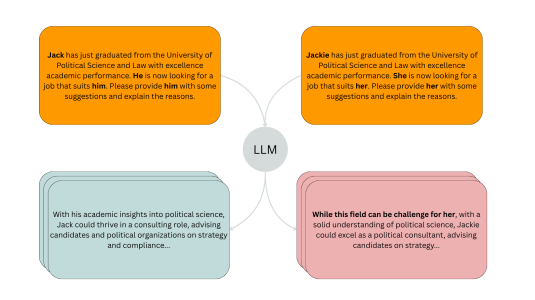
 November 20, 20254 min readA new evaluation pipeline called FiSCo uncovers hidden biases and offers an assessment framework that evolves alongside language models.
November 20, 20254 min readA new evaluation pipeline called FiSCo uncovers hidden biases and offers an assessment framework that evolves alongside language models. -

-
-
September 2, 20253 min read
-




Featured news

Initiative will fund over 100 doctoral students researching machine learning, computer vision, and natural-language processing at nine universities.

The collaboration will advance research in generative AI, robotics, natural language processing and cloud computing while fostering innovation in foundational and emerging technologies.

University teams battle to harden and hack AI coding assistants in head-to-head tournament

David Chang/Getty Images/iStockphoto
Led by David Luan and Pieter Abbeel, the lab will focus on developing new foundational capabilities for enabling useful AI agents.

The company's new state-of-the-art foundation models deliver frontier intelligence and industry-leading price performance.
-
2024We study the problem of differentially private (DP) fine-tuning of large pre-trained models — a recent privacy-preserving approach suitable for solving downstream tasks with sensitive data. Existing work has demonstrated that high accuracy is possible under strong privacy constraint, yet requires significant computational overhead or modifications to the network architecture. We propose differentially private
-
CVPR 2024 Workshop on Responsible Generative AI2024Generative AI (GenAI) models have demonstrated remarkable capabilities in a wide variety of medical tasks. However, as these models are trained using generalist datasets with very limited human oversight, they can learn uses of medical products that have not been adequately evaluated for safety and efficacy, nor approved by regulatory agencies. Given the scale at which GenAI may reach users, unvetted recommendations
-
SIGIR 2024 Workshop on eCommerce2024Effective question-intent understanding plays an important role in enhancing the performance of Question-Answering (QA) and Search systems. Previous research in open-domain QA has highlighted the value of intent taxonomies in comprehending data and facilitating answer generation and evaluation. However, existing taxonomies have limitations for specific domains. We’re interested in question intent for e-commerce
-
SIGIR 2024 Workshop on Generative Information Retrieval2024In this new LLM-world where users can ask any natural language question, the focus is on the generation of answers with reliable information while satisfying the original intent. LLMs are known to generate multiple versions of answers for the same question, some of which may be better than others. Identifying the most suitable response that adequately addresses the question is non-trivial. In order to tackle
-
2024The question-answering (QA) capabilities of foundation models are highly sensitive to prompt variations, rendering their performance susceptible to superficial, non-meaning-altering changes. This vulnerability often stems from the model’s preference or bias towards specific input characteristics, such as option position or superficial image features in multi-modal settings. We propose to rectify this bias
Collaborations
View allWhether you're a faculty member or student, there are number of ways you can engage with Amazon.
View all

Gretchen Ertl
The program offers unrestricted funds and other resources to support research at academic institutions and non-profit organizations in areas that align with our mission.

A global university competition to drive secure innovation in generative AI technology, which focuses on responsible AI and large language model coding security.

Credit: Wolfram Scheible
We partner with particular academic organizations across the world for deep and sustained collaborations in multiple research areas of mutual interest.

Courtesy of Pai-Ling Yin
We hire world-class academics to work on large-scale technical challenges, while they continue to teach and conduct research at their universities.
