
Top eight university teams move on to head-to-head finals focused on AI security for code generation.

In 2017, IEEE Internet Computing identified a single paper from its publication history that had best withstood the test of time: a 2003 paper called “Amazon.com Recommendations: Item-to-Item Collaborative Filtering”

A new multimodal foundation model that unifies speech and text processing in a single architecture, delivering frontier voice intelligence and industry-leading price performance.

F4D Studios
How Amazon’s scientists developed a first-of-its-kind multi-echelon system for inventory buying and placement.

We present Amazon Nova Premier, our most capable multimodal foundation model and teacher for model distillation.
Customer-obsessed science


Research areas













-
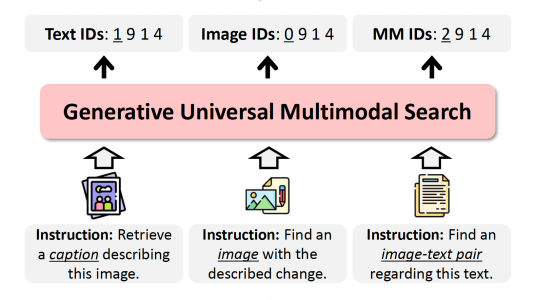
 June 25, 2025With large datasets, directly generating data ID codes from query embeddings is much more efficient than performing pairwise comparisons between queries and candidate responses.
June 25, 2025With large datasets, directly generating data ID codes from query embeddings is much more efficient than performing pairwise comparisons between queries and candidate responses.




Featured news

Top eight university teams move on to head-to-head finals focused on AI security for code generation.

David Chang/Getty Images/iStockphoto
Led by David Luan and Pieter Abbeel, the lab will focus on developing new foundational capabilities for enabling useful AI agents.

The company's new state-of-the-art foundation models deliver frontier intelligence and industry-leading price performance.
-
2025We introduce SIFT (Speech Instruction FineTuning), a 50M-example dataset designed for instruction fine-tuning and pre-training of speech-text large language models (LLMs). SIFT-50M is built from publicly available speech corpora, which collectively contain 14K hours of speech, and leverages LLMs along with off-the-shelf expert models. The dataset spans five languages, encompassing a diverse range of speech
-
2025Retrieval Augmented Generation (RAG) has emerged as a powerful application of Large Language Models (LLMs), revolutionizing information search and consumption. RAG systems combine traditional search capabilities with LLMs to generate comprehensive answers to user queries, ideally with accurate citations. However, in our experience of developing a RAG product, LLMs often struggle with source attribution,
-
2025Safety reasoning is a recent paradigm where LLMs reason over safety policies before generating responses, thereby mitigating limitations in existing safety measures such as over-refusal and jailbreak vulnerabilities. However, implementing this paradigm is challenging due to the resource-intensive process of creating high-quality policy-embedded chain-of-thought (CoT) datasets while ensuring reasoning remains
-
ACL Findings 20252025Dense embeddings are fundamental to modern machine learning systems, powering Retrieval Augmented Generation (RAG), information retrieval, and representation learning. While instruction-conditioning has become the dominant approach for embedding specialization, its direct application to low-capacity models imposes fundamental representational constraints that limit the performance gains derived from specialization
-
2025Ambiguous user queries pose a significant challenge in task-oriented dialogue systems relying on information retrieval. While Large Language Models (LLMs) have shown promise in generating clarification questions to tackle query ambiguity, they rely solely on the topk retrieved documents for clarification which fails when ambiguity is too high to retrieve relevant documents in the first place. Traditional
Academia
View allWhether you're a faculty member or student, there are number of ways you can engage with Amazon.
View all

Gretchen Ertl
The program offers unrestricted funds and other resources to support research at academic institutions and non-profit organizations in areas that align with our mission.
A global university competition to drive secure innovation in generative AI technology, which focuses on responsible AI and large language model coding security.

Credit: Wolfram Scheible
We partner with particular academic organizations across the world for deep and sustained collaborations in multiple research areas of mutual interest.

Courtesy of Pai-Ling Yin
We hire world-class academics to work on large-scale technical challenges, while they continue to teach and conduct research at their universities.
