
Audible's ML algorithms connect users directly to relevant titles, reducing the number of purchase steps for millions of daily users.

With a novel parallel-computing architecture, a CAD-to-USD pipeline, and the use of OpenUSD as ground truth, a new simulator can explore hundreds of sensor configurations in the time it takes to test just a few physical setups.

From reimagining storage to serverless computing, Aurora continues to push the boundaries of what's possible in database technology.

Amazon VP and distinguished scientist Byron Cook explains how AWS's new Automated Reasoning checks address key challenges in automated reasoning: translating natural to structured language, defining truth, and definitive reasoning.

Trained on millions of hours of data from Amazon fulfillment centers and sortation centers, Amazon’s new DeepFleet models predict future traffic patterns for fleets of mobile robots.
Customer-obsessed science


Research areas













-
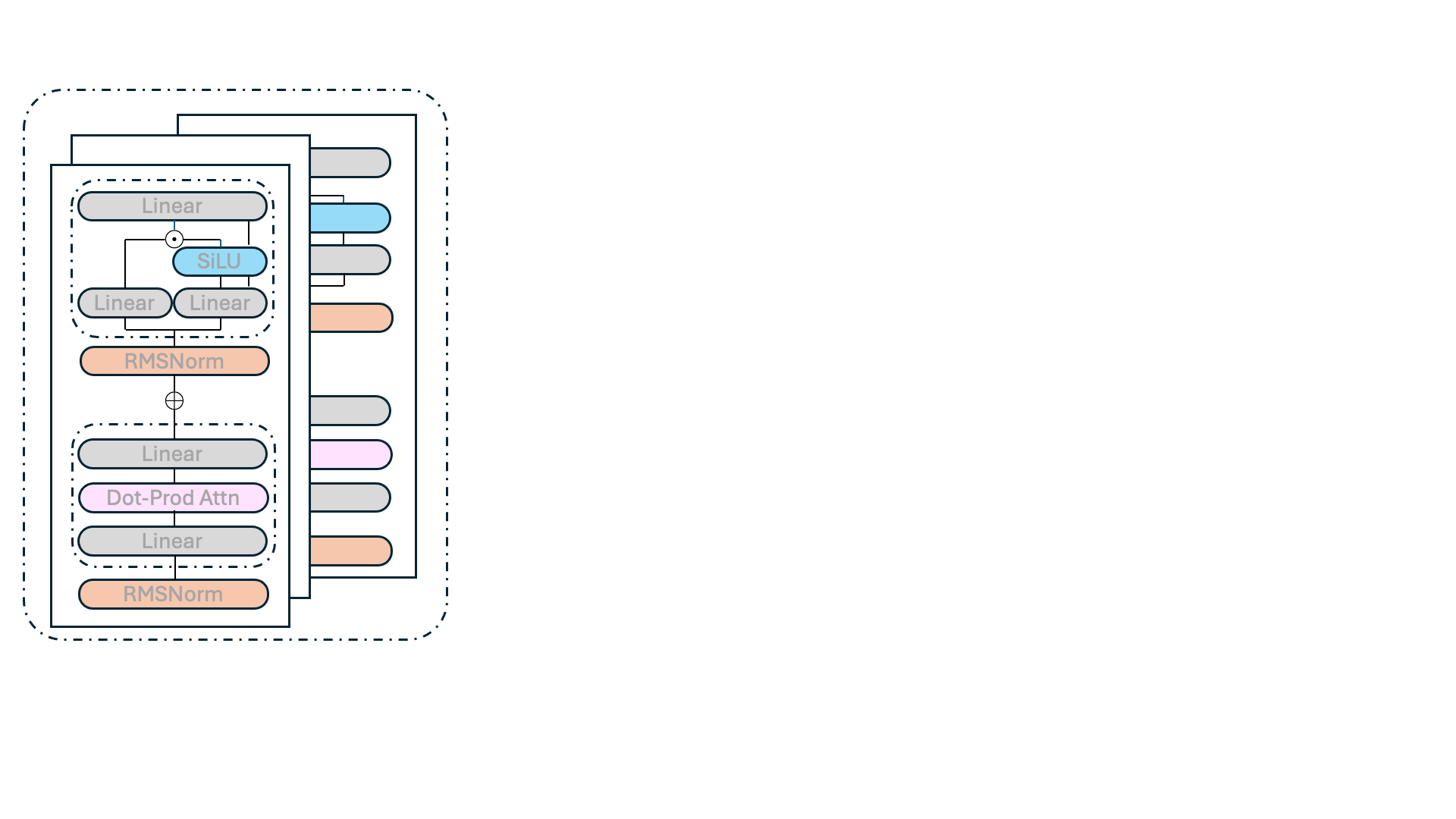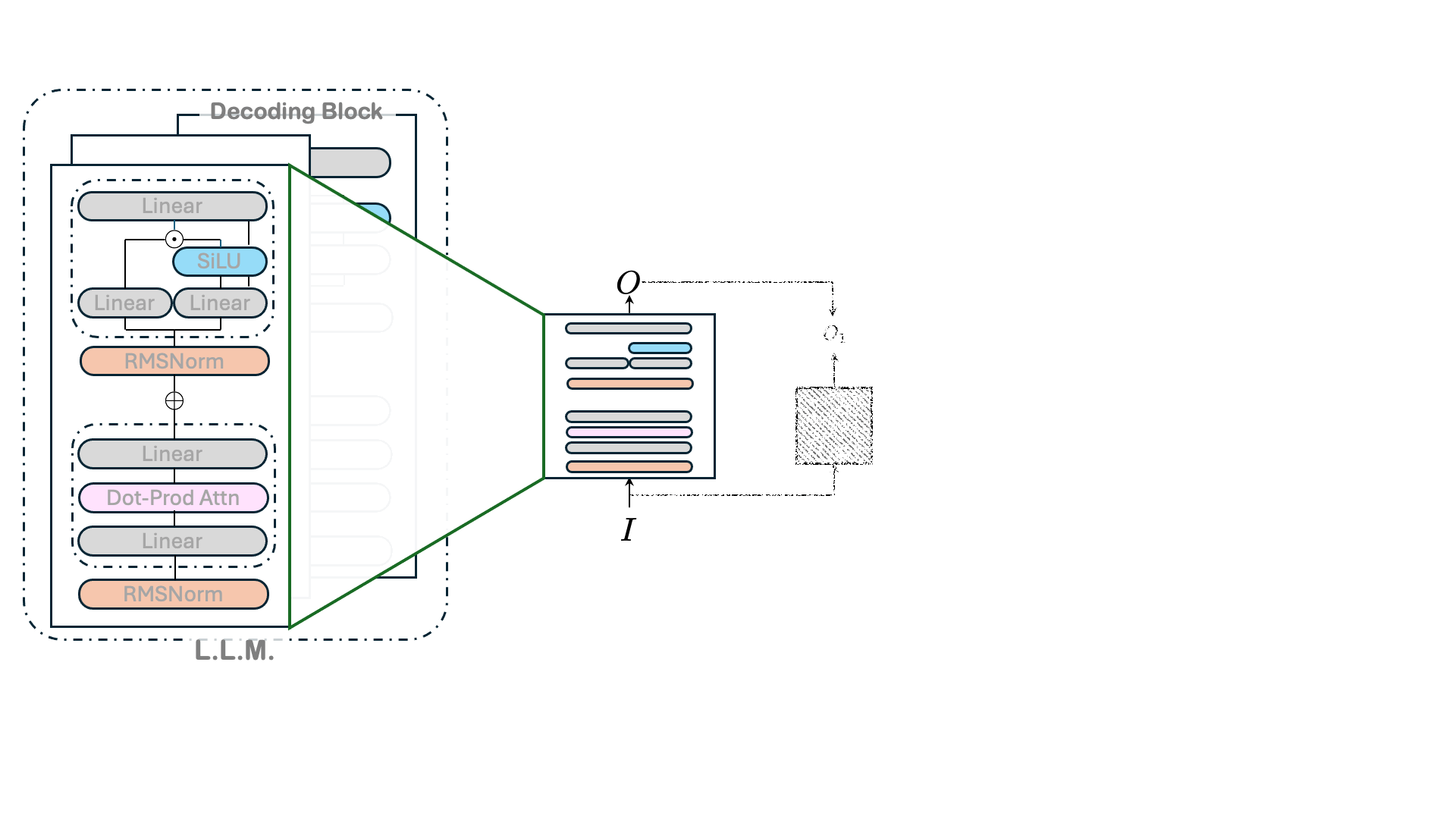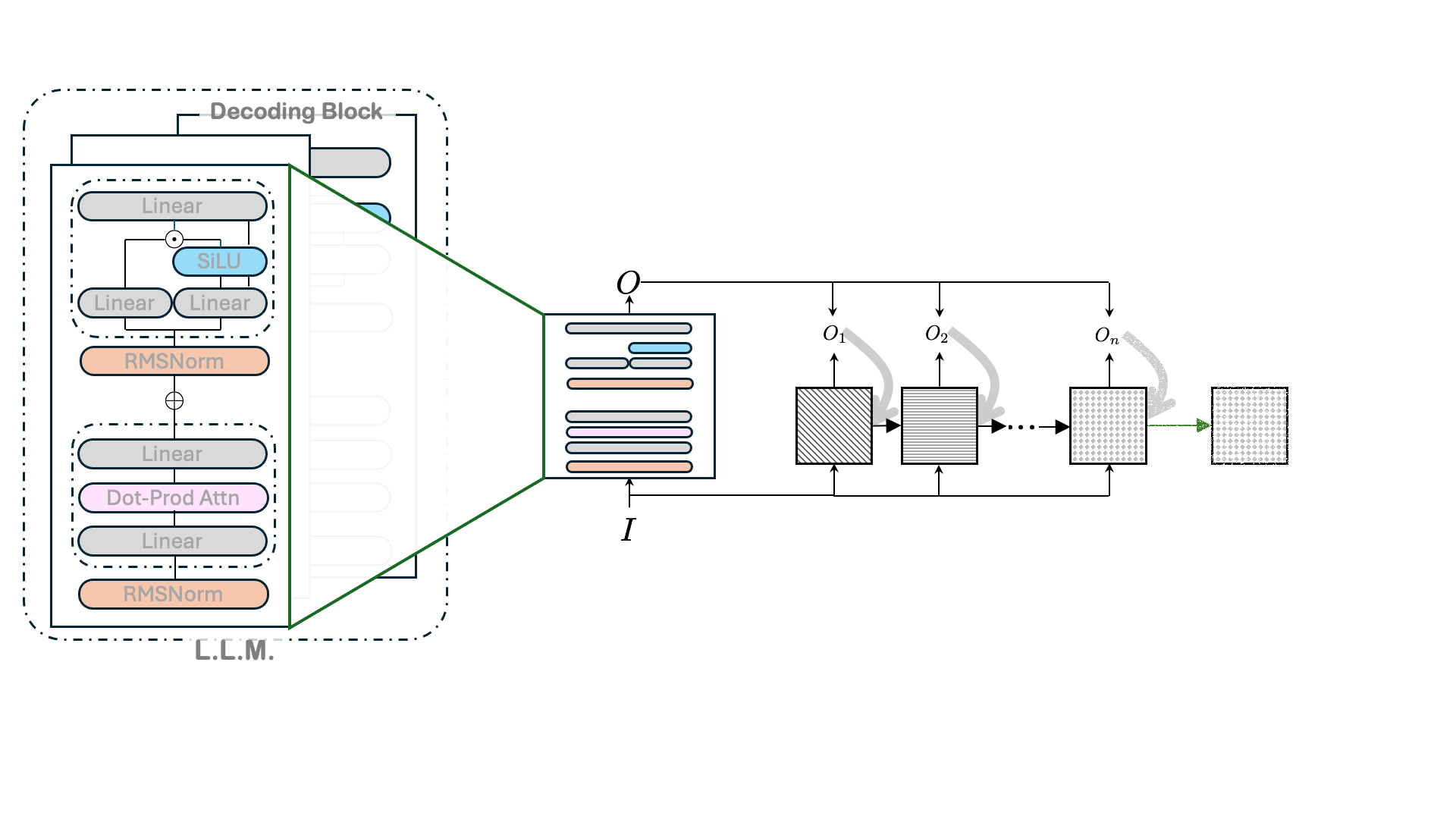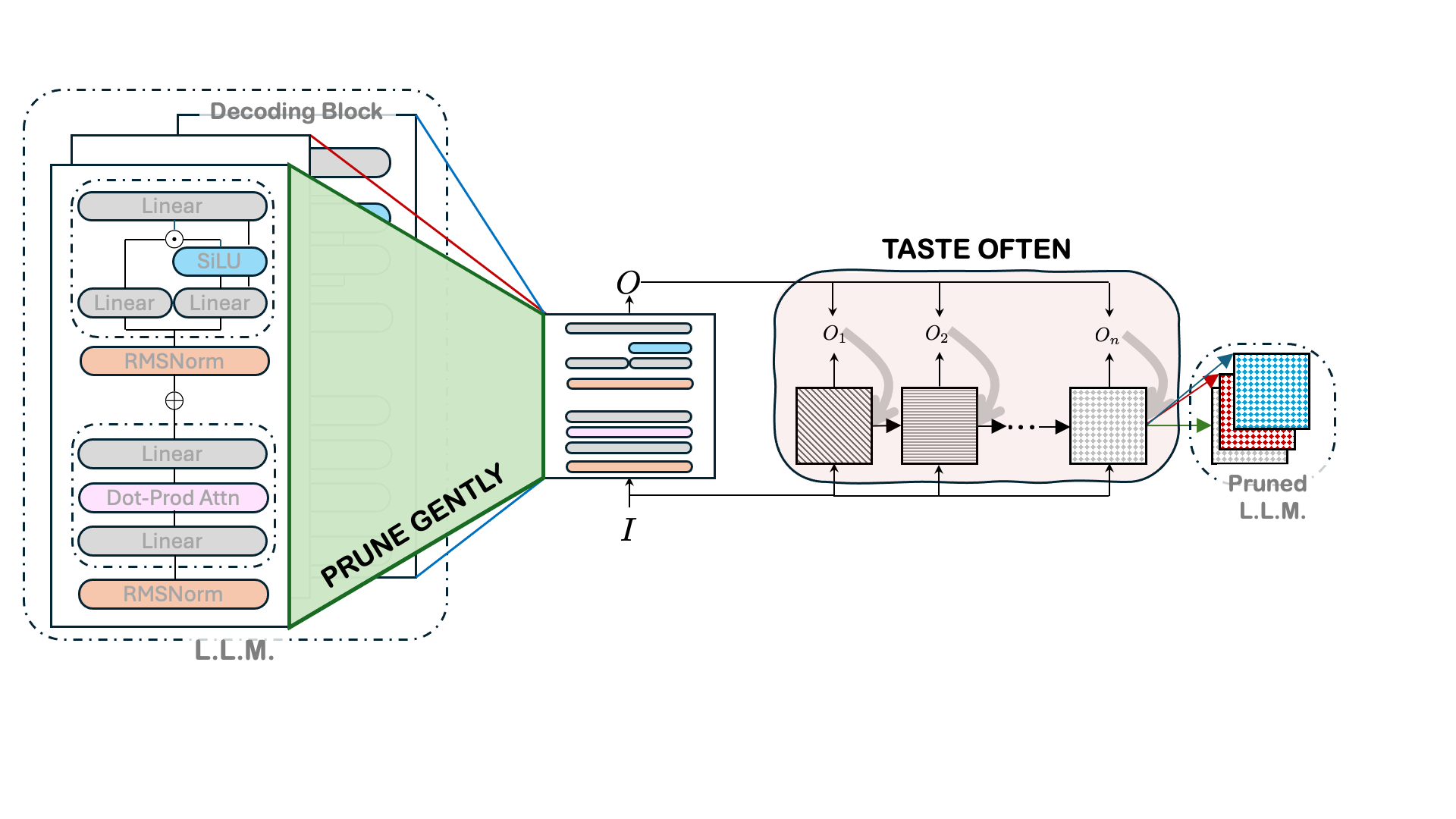
 August 8, 2025A new philosophy for developing LLM architectures reduces energy requirements, speeds up runtime, and preserves pretrained-model performance.
August 8, 2025A new philosophy for developing LLM architectures reduces energy requirements, speeds up runtime, and preserves pretrained-model performance.




Featured news

University teams battle to harden and hack AI coding assistants in head-to-head tournament

David Chang/Getty Images/iStockphoto
Led by David Luan and Pieter Abbeel, the lab will focus on developing new foundational capabilities for enabling useful AI agents.

The company's new state-of-the-art foundation models deliver frontier intelligence and industry-leading price performance.
-
2024Most multimodal large language models (MLLMs) learn language-to-object grounding through causal language modeling where grounded objects are captured by bounding boxes as sequences of location tokens. This paradigm lacks pixel-level representations that are impor- tant for fine-grained visual understanding and diagnosis. In this work, we introduce GROUNDHOG, an MLLM developed by grounding Large Language
-
2024Retrieval Augmented Generation (RAG) is emerging as a flexible and robust technique to adapt models to private users data without training, to handle credit attribution, and to allow efficient machine unlearning at scale. However, RAG techniques for image generation may lead to parts of the retrieved samples being copied in the model’s output. To reduce risks of leaking private information contained in
-
2024Large Language Models (LLMs) have shown great ability in solving traditional natural-language tasks and elementary reasoning tasks with appropriate prompting techniques. However, their ability is still limited in solving complicated science problems. In this work, we aim to push the upper bound of the reasoning capability of LLMs by proposing a collaborative multi-agent, multi-reasoning-path (CoMM) prompting
-
2024Grounded text generation, encompassing tasks such as long-form question-answering and summarization, necessitates both content selection and content consolidation. Current end-to-end methods are difficult to control and interpret due to their opaqueness. Accordingly, recent works have proposed a modular approach, with separate components for each step. Specifically, we focus on the second subtask, of generating
-
2024Open-world detection poses significant challenges, as it requires the detection of any object using either object class labels or free-form texts. Existing related works often use large-scale manual annotated caption datasets for training, which are extremely expensive to collect. Instead, we propose to transfer knowledge from vision-language models (VLMs) to enrich the open-vocabulary descriptions automatically
Academia
View allWhether you're a faculty member or student, there are number of ways you can engage with Amazon.
View all

Gretchen Ertl
The program offers unrestricted funds and other resources to support research at academic institutions and non-profit organizations in areas that align with our mission.

A global university competition to drive secure innovation in generative AI technology, which focuses on responsible AI and large language model coding security.

Credit: Wolfram Scheible
We partner with particular academic organizations across the world for deep and sustained collaborations in multiple research areas of mutual interest.

Courtesy of Pai-Ling Yin
We hire world-class academics to work on large-scale technical challenges, while they continue to teach and conduct research at their universities.
