
Audible's ML algorithms connect users directly to relevant titles, reducing the number of purchase steps for millions of daily users.

With a novel parallel-computing architecture, a CAD-to-USD pipeline, and the use of OpenUSD as ground truth, a new simulator can explore hundreds of sensor configurations in the time it takes to test just a few physical setups.

From reimagining storage to serverless computing, Aurora continues to push the boundaries of what's possible in database technology.

Amazon VP and distinguished scientist Byron Cook explains how AWS's new Automated Reasoning checks address key challenges in automated reasoning: translating natural to structured language, defining truth, and definitive reasoning.

Trained on millions of hours of data from Amazon fulfillment centers and sortation centers, Amazon’s new DeepFleet models predict future traffic patterns for fleets of mobile robots.
Customer-obsessed science


Research areas













-
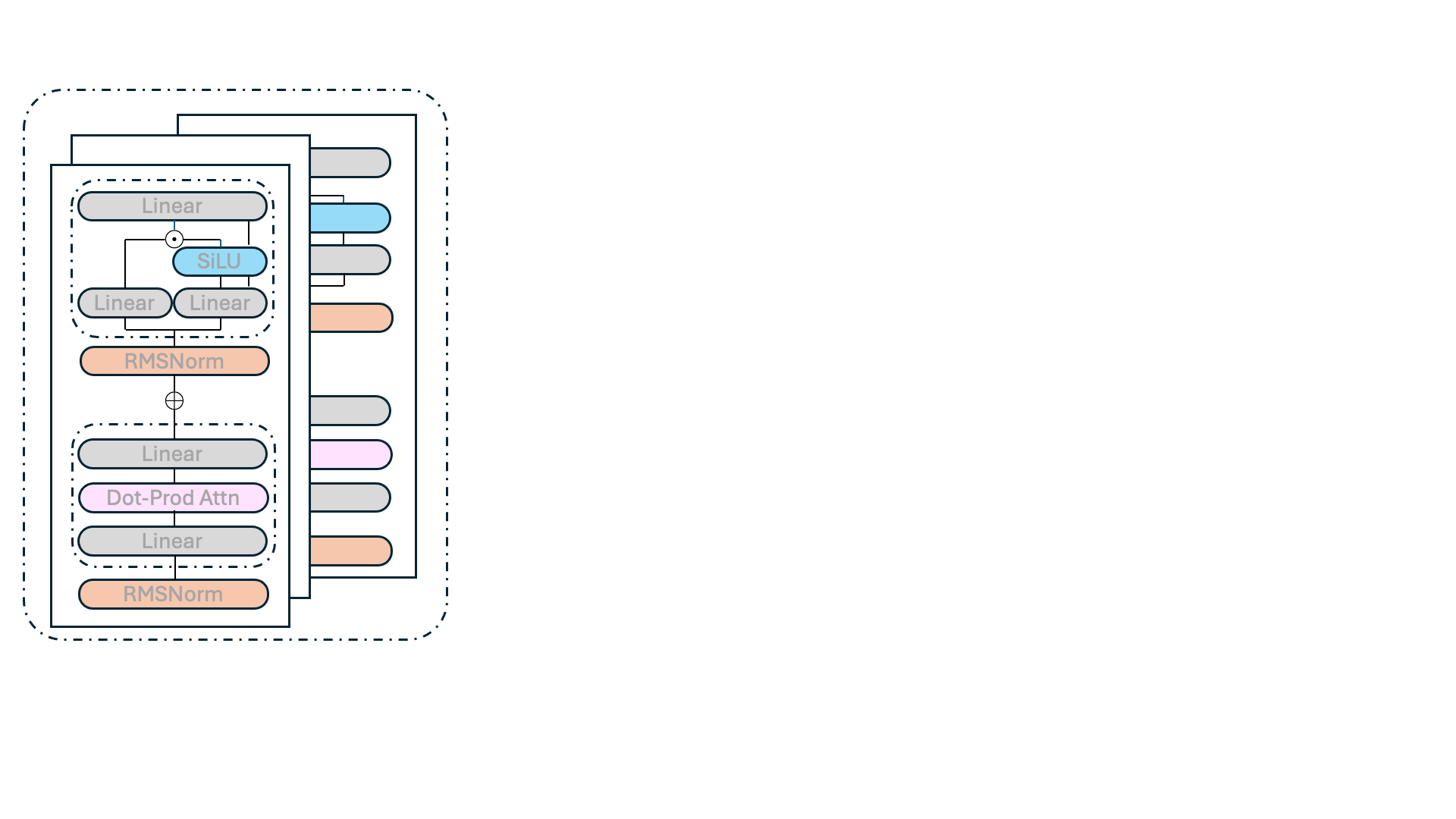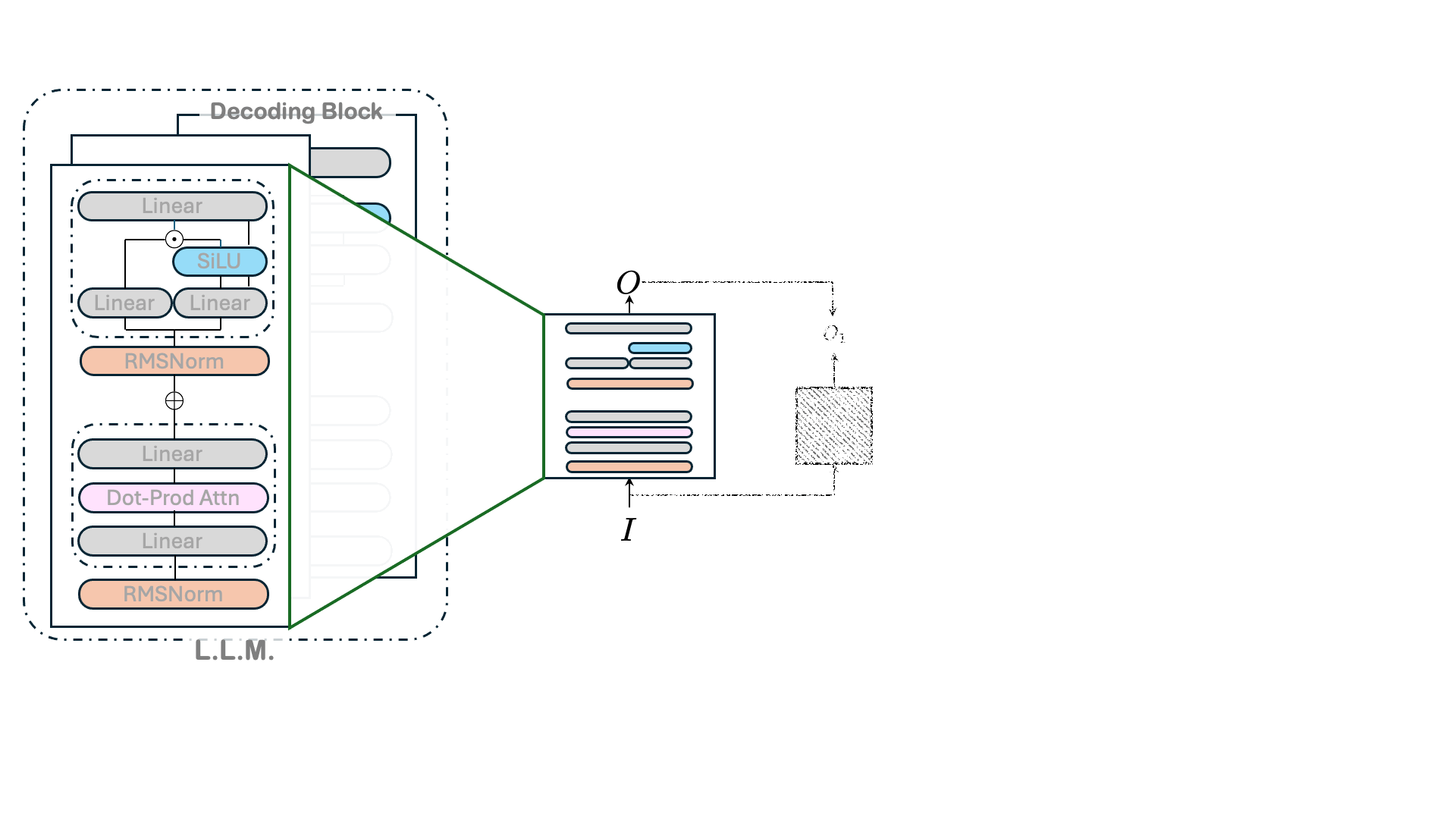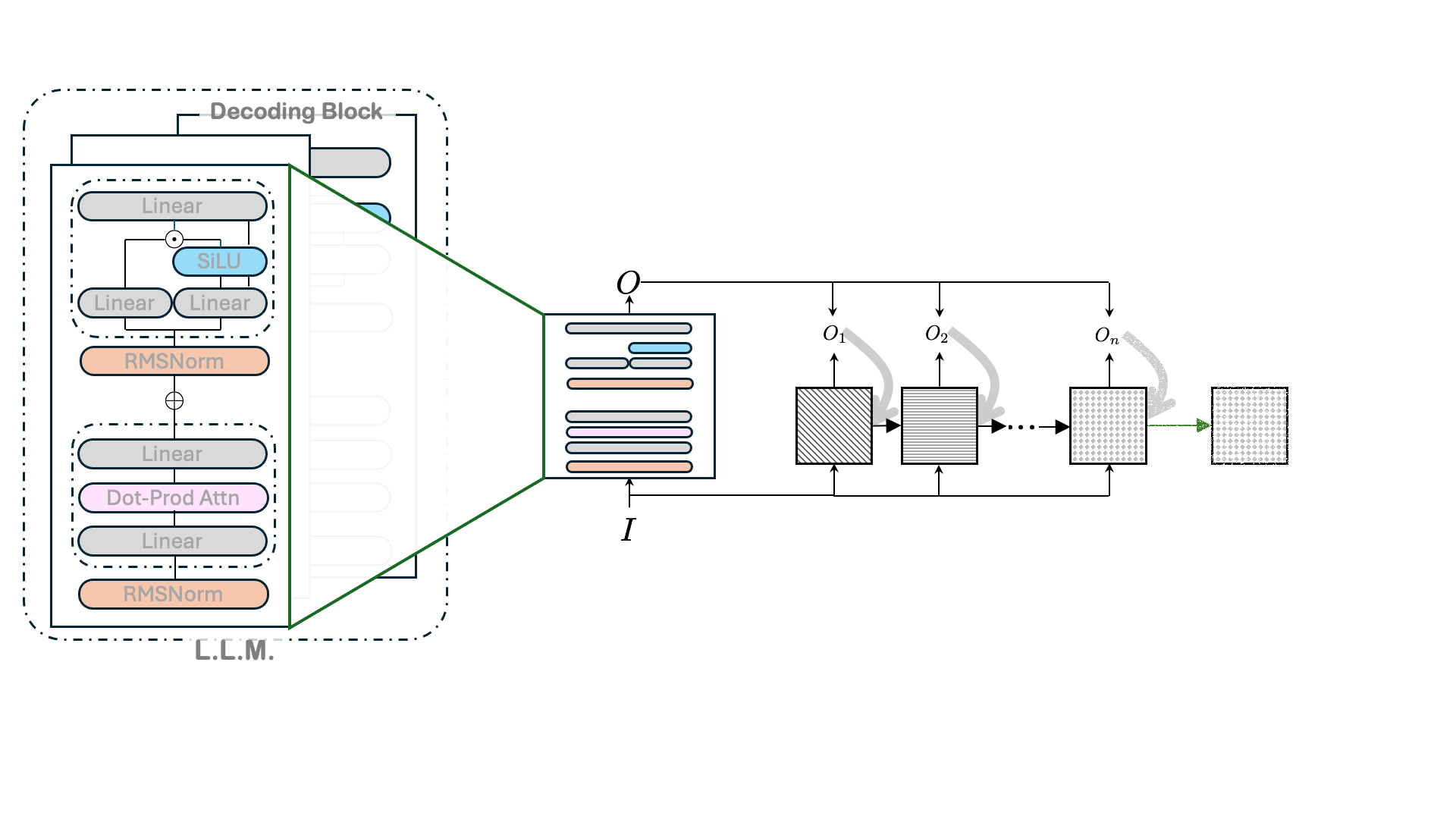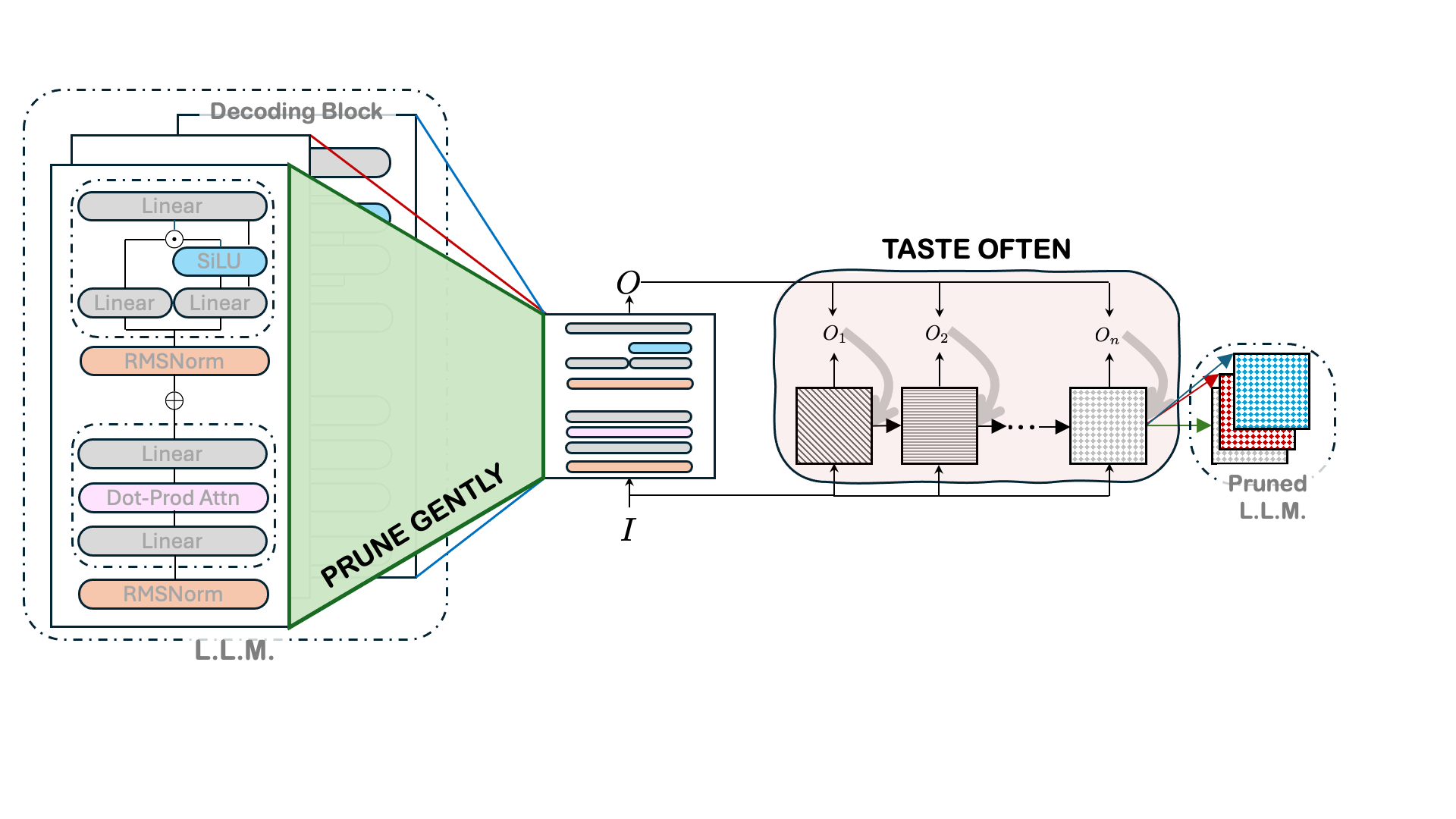
 August 8, 2025A new philosophy for developing LLM architectures reduces energy requirements, speeds up runtime, and preserves pretrained-model performance.
August 8, 2025A new philosophy for developing LLM architectures reduces energy requirements, speeds up runtime, and preserves pretrained-model performance.




Featured news

University teams battle to harden and hack AI coding assistants in head-to-head tournament

David Chang/Getty Images/iStockphoto
Led by David Luan and Pieter Abbeel, the lab will focus on developing new foundational capabilities for enabling useful AI agents.

The company's new state-of-the-art foundation models deliver frontier intelligence and industry-leading price performance.
-
2024Large language models (LLMs) tend to inadequately integrate input context during text generation, relying excessively on encoded prior knowledge in model parameters, potentially resulting in generated text with factual inconsistencies or contextually unfaithful content. LLMs utilize two primary knowledge sources: 1) prior (parametric) knowledge from pretraining, and 2) contextual (non-parametric) knowledge
-
2024Dictionary example sentences play an important role in illustrating word definitions and usage, but manually creating quality sentences is challenging. Prior works have demonstrated that language models can be trained to generate example sentences. However, they relied on costly customized models and word sense datasets for generation and evaluation of their work. Rapid advancements in foundational models
-
2024Diffusion-based generative modeling has been achieving state-of-the-art results on various generation tasks. Most diffusion models, however, are limited to a single-generation modeling. Can we generalize diffusion models with the ability of multi-modal generative training for more generalizable modeling? In this paper, we propose a principled way to define a diffusion model by constructing a unified multi-modal
-
Fine-tuning language models (LMs) has demonstrated success in a wide array of downstream tasks. However, as LMs are scaled up, the memory requirements for backpropagation become prohibitively high. Zeroth-order (ZO) optimization methods can leverage memory-efficient for-ward passes to estimate gradients. Recently, MeZO, an adaptation of ZO-SGD, has been shown to consistently outperform zero-shot and in-context
-
2024Reinforcement learning from human feedback (RLHF) has been extensively employed to align large language models with user intent. However, proximal policy optimization (PPO) based RLHF is occasionally unstable requiring significant hyperparameter finetuning, and computationally expensive to maximize the estimated reward during alignment. Recently, direct preference optimization (DPO) is proposed to address
Academia
View allWhether you're a faculty member or student, there are number of ways you can engage with Amazon.
View all

Gretchen Ertl
The program offers unrestricted funds and other resources to support research at academic institutions and non-profit organizations in areas that align with our mission.

A global university competition to drive secure innovation in generative AI technology, which focuses on responsible AI and large language model coding security.

Credit: Wolfram Scheible
We partner with particular academic organizations across the world for deep and sustained collaborations in multiple research areas of mutual interest.

Courtesy of Pai-Ling Yin
We hire world-class academics to work on large-scale technical challenges, while they continue to teach and conduct research at their universities.
