
From reimagining storage to serverless computing, Aurora continues to push the boundaries of what's possible in database technology.

Amazon VP and distinguished scientist Byron Cook explains how AWS's new Automated Reasoning checks address key challenges in automated reasoning: translating natural to structured language, defining truth, and definitive reasoning.

Trained on millions of hours of data from Amazon fulfillment centers and sortation centers, Amazon’s new DeepFleet models predict future traffic patterns for fleets of mobile robots.

A new philosophy for developing LLM architectures reduces energy requirements, speeds up runtime, and preserves pretrained-model performance.
Customer-obsessed science


Research areas













-
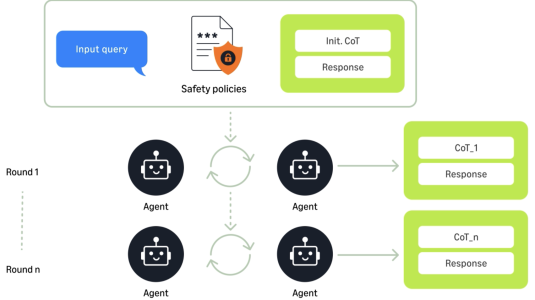
 July 31, 2025Using ensembles of agents to generate and refine interactions annotated with chains of thought improves performance on a battery of benchmarks by an average of 29%.
July 31, 2025Using ensembles of agents to generate and refine interactions annotated with chains of thought improves performance on a battery of benchmarks by an average of 29%.




Featured news

University teams battle to harden and hack AI coding assistants in head-to-head tournament

David Chang/Getty Images/iStockphoto
Led by David Luan and Pieter Abbeel, the lab will focus on developing new foundational capabilities for enabling useful AI agents.

The company's new state-of-the-art foundation models deliver frontier intelligence and industry-leading price performance.
-
2024Recent video masked autoencoder (MAE) works have de-signed improved masking algorithms focused on saliency. These works leverage visual cues such as motion to mask the most salient regions. However, the robustness of such visual cues depends on how often input videos match underlying assumptions. On the other hand, natural language description is an information dense representation of video that implicitly
-
IEEE Sensors2024Continuous back posture monitoring and correction can help to prevent back pains associated with improper back postures. However, existing solutions are expensive, use wearable sensors which usually require regular maintenance, or use cameras which have privacy issues. We introduce Di-Angle, a low-cost, battery-free, and reusable sensor capable of monitoring harmful back angles with high accuracy. Our novel
-
2024A complementary item is an item that pairs well with another item when consumed together. In the context of e-commerce, providing recommendations for complementary items is essential for both customers and stores. Current models for suggesting complementary items often rely heavily on user behavior data, such as co-purchase relationships. However, just because two items are frequently bought together does
-
2024Handling drafty partial code remains a notable challenge in real-time code suggestion applications. Previous work has demonstrated shortcomings of large language models of code (CodeLLMs) in completing partial code with potential bugs. In this study, we view partial code as implementation hints and fine-tune CodeLLMs to jointly rewrite and complete partial code into functional full programs. We explore
-
We investigate the use of in-context learning and prompt engineering to estimate the contributions of training data in the outputs of instruction-tuned large language models (LLMs). We propose two novel approaches: (1) a similarity-based approach that measures the difference between LLM out-puts with and without provided context, and (2) a mixture distribution model approach that frames the problem of identifying
Academia
View allWhether you're a faculty member or student, there are number of ways you can engage with Amazon.
View all

Gretchen Ertl
The program offers unrestricted funds and other resources to support research at academic institutions and non-profit organizations in areas that align with our mission.

A global university competition to drive secure innovation in generative AI technology, which focuses on responsible AI and large language model coding security.

Credit: Wolfram Scheible
We partner with particular academic organizations across the world for deep and sustained collaborations in multiple research areas of mutual interest.

Courtesy of Pai-Ling Yin
We hire world-class academics to work on large-scale technical challenges, while they continue to teach and conduct research at their universities.
