
Unique end-of-arm tools with three-dimensional force sensors and innovative control algorithms enable robotic arms to “pick” items from and “stow” items in fabric storage pods.

We present Amazon Nova Premier, our most capable multimodal foundation model and teacher for model distillation.

In experiments involving real quantum devices and algorithms, automated-reasoning-based method for mapping quantum computations onto quantum circuits is 26 times as fast as predecessors.

A new multimodal foundation model that unifies speech and text processing in a single architecture, delivering frontier voice intelligence and industry-leading price performance.

Novel training procedure and decoding mechanism enable model to outperform much larger foundation model prompted to perform the same task.
Customer-obsessed science


Research areas













-
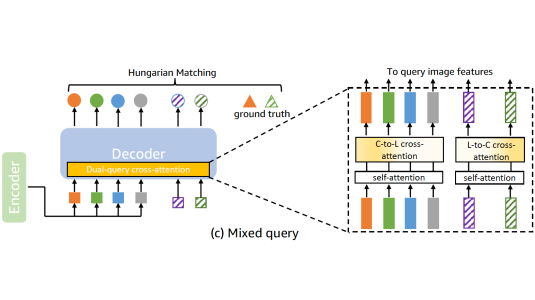
 June 12, 2025Novel architecture that fuses learnable queries and conditional queries improves a segmentation model’s ability to transfer across tasks.
June 12, 2025Novel architecture that fuses learnable queries and conditional queries improves a segmentation model’s ability to transfer across tasks.




Featured news

Inaugural global university competition focused on advancing secure, trusted AI-assisted software development.

David Chang/Getty Images/iStockphoto
Led by David Luan and Pieter Abbeel, the lab will focus on developing new foundational capabilities for enabling useful AI agents.

The company's new state-of-the-art foundation models deliver frontier intelligence and industry-leading price performance.
-
2025Composed Image Retrieval (CIR) is a complex task that aims to retrieve images based on a multimodal query. Typical training data consists of triplets containing a reference image, a textual description of desired modifications, and the target image, which are expensive and time-consuming to acquire. The scarcity of CIR datasets has led to zero-shot approaches utilizing synthetic triplets or leveraging vision-language
-
2025Open domain question answering systems frequently rely on information retrieved from large collections of text (such as the Web) to answer questions. However, such collections of text often contain conflicting information, and indiscriminately depending on this information may result in untruthful and inaccurate answers. To understand the gravity of this problem, we collect a human-annotated dataset, Question
-
AISTATS 20252025We study the well-motivated problem of online distribution shift in which the data arrive in batches and the distribution of each batch can change arbitrarily over time. Since the shifts can be large or small, abrupt or gradual, the length of the relevant historical data to learn from may vary over time, which poses a major challenge in designing algorithms that can automatically adapt to the best “attention
-
2025We introduce AnoLLM, a novel framework that leverages large language models (LLMs) for unsupervised tabular anomaly detection. By converting tabular data into a standardized text format, we further adapt a pre-trained LLM with this serialized data, and assign anomaly scores based on the negative log likelihood generated by the LLM. Unlike traditional methods that can require extensive feature engineering
-
CLeaR 20252025We propose a new approach to falsify causal discovery algorithms without ground truth, which is based on testing the causal model on a variable pair excluded during learning the causal model. Specifically, given data on X,Y,Z = X,Y,Z1,...,Zk, we apply the causal discovery algorithm separately to the ’leave-one-out’ data sets X,Z and Y,Z. We demonstrate that the two resulting causal models, in the form of
Academia
View allWhether you're a faculty member or student, there are number of ways you can engage with Amazon.
View all

Gretchen Ertl
The program offers unrestricted funds and other resources to support research at academic institutions and non-profit organizations in areas that align with our mission.

A global university competition to drive secure innovation in generative AI technology, which focuses on responsible AI and large language model coding security.

Credit: Wolfram Scheible
We partner with particular academic organizations across the world for deep and sustained collaborations in multiple research areas of mutual interest.

Courtesy of Pai-Ling Yin
We hire world-class academics to work on large-scale technical challenges, while they continue to teach and conduct research at their universities.
