
In 2017, IEEE Internet Computing identified a single paper from its publication history that had best withstood the test of time: a 2003 paper called “Amazon.com Recommendations: Item-to-Item Collaborative Filtering”

F4D Studios
How Amazon’s scientists developed a first-of-its-kind multi-echelon system for inventory buying and placement.

Top eight university teams move on to head-to-head finals focused on AI security for code generation.

We present Amazon Nova Premier, our most capable multimodal foundation model and teacher for model distillation.

A new multimodal foundation model that unifies speech and text processing in a single architecture, delivering frontier voice intelligence and industry-leading price performance.
Customer-obsessed science


Research areas













-
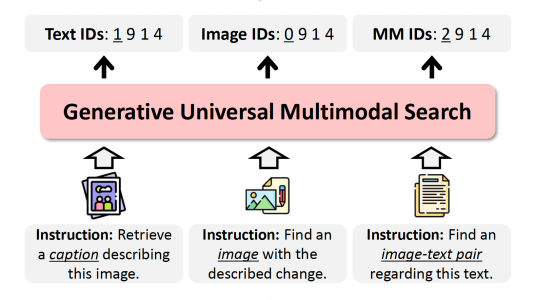
 June 25, 2025With large datasets, directly generating data ID codes from query embeddings is much more efficient than performing pairwise comparisons between queries and candidate responses.
June 25, 2025With large datasets, directly generating data ID codes from query embeddings is much more efficient than performing pairwise comparisons between queries and candidate responses.




Featured news

Top eight university teams move on to head-to-head finals focused on AI security for code generation.

David Chang/Getty Images/iStockphoto
Led by David Luan and Pieter Abbeel, the lab will focus on developing new foundational capabilities for enabling useful AI agents.

The company's new state-of-the-art foundation models deliver frontier intelligence and industry-leading price performance.
-
2025In high-stakes industrial NLP applications, balancing generation quality with speed and efficiency presents significant challenges. We address them by investigating two complementary optimization approaches: Medusa for speculative decoding and knowledge distillation (KD) for model compression. We demonstrate the practical application of these techniques in real-world travel domain tasks, including trip
-
2025Autoregressive next-token prediction with the Transformer decoder has become a de facto standard in large language models (LLMs), achieving remarkable success in Natural Language Processing (NLP) at scale. Extending this paradigm to audio poses unique challenges due to its inherently continuous nature. We research audio generation with a causal language model (LM) without discrete tokens. We leverage token-wise
-
2025Text chunking is fundamental to modern retrieval-augmented systems, yet existing methods often struggle with maintaining semantic coherence, both within and across chunks, while dealing with document structure and noise. We present AutoChunker, a bottom-up approach for text chunking that combines document structure awareness with noise elimination. AutoChunker leverages language models to identify and segregate
-
SIGMOD/PODS 2025 Workshop on Data Management on New Hardware2025We present insert-optimized implementations of three fundamental data sketching algorithms: Count Sketch (CS), SpaceSaving (SS), and Karnin-Lang-Liberty (KLL).While these sketches are widely used for approximate query processing and stream analytics, their practical insert performance often falls short of their full potential. Through careful engineering and novel implementation strategies, we achieve substantial
-
IEEE ICIP 20252025Copy Detection system aims to identify if a query image is an edited/manipulated copy of an image from a large reference database with millions of images. While global image descriptors can retrieve visually similar images, they struggle to differentiate near-duplicates from semantically similar instances. We propose a dual-triplet metric learning (DTML) technique to learn global image features that group
Academia
View allWhether you're a faculty member or student, there are number of ways you can engage with Amazon.
View all

Gretchen Ertl
The program offers unrestricted funds and other resources to support research at academic institutions and non-profit organizations in areas that align with our mission.
A global university competition to drive secure innovation in generative AI technology, which focuses on responsible AI and large language model coding security.

Credit: Wolfram Scheible
We partner with particular academic organizations across the world for deep and sustained collaborations in multiple research areas of mutual interest.

Courtesy of Pai-Ling Yin
We hire world-class academics to work on large-scale technical challenges, while they continue to teach and conduct research at their universities.
