
Top eight university teams move on to head-to-head finals focused on AI security for code generation.

In 2017, IEEE Internet Computing identified a single paper from its publication history that had best withstood the test of time: a 2003 paper called “Amazon.com Recommendations: Item-to-Item Collaborative Filtering”

A new multimodal foundation model that unifies speech and text processing in a single architecture, delivering frontier voice intelligence and industry-leading price performance.

F4D Studios
How Amazon’s scientists developed a first-of-its-kind multi-echelon system for inventory buying and placement.

We present Amazon Nova Premier, our most capable multimodal foundation model and teacher for model distillation.
Customer-obsessed science


Research areas













-
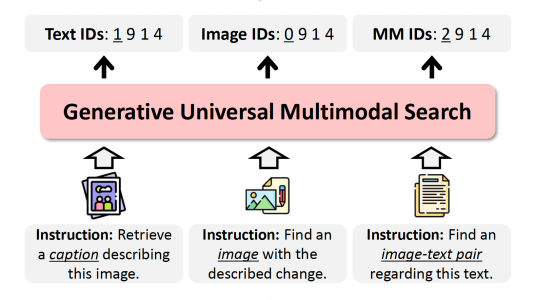
 June 25, 2025With large datasets, directly generating data ID codes from query embeddings is much more efficient than performing pairwise comparisons between queries and candidate responses.
June 25, 2025With large datasets, directly generating data ID codes from query embeddings is much more efficient than performing pairwise comparisons between queries and candidate responses.




Featured news

Top eight university teams move on to head-to-head finals focused on AI security for code generation.

David Chang/Getty Images/iStockphoto
Led by David Luan and Pieter Abbeel, the lab will focus on developing new foundational capabilities for enabling useful AI agents.

The company's new state-of-the-art foundation models deliver frontier intelligence and industry-leading price performance.
-
2025Effectively selecting data from population subgroups where a model performs poorly is crucial for improving its performance. Traditional methods for identifying these subgroups often rely on sensitive information, raising privacy issues. Additionally, gathering such information at runtime might be impractical. This paper introduces a cost-effective strategy that addresses these concerns. We identify underperforming
-
2025Goal-oriented script planning, or the ability to plan coherent sequences of actions toward specific goals, is commonly used by humans to plan for daily activities. In e-commerce, customers increasingly seek LLM-based assistants to plan for them with a script and recommend products at each step, thereby facilitating convenient and efficient shopping experiences. However, this capability remains under-explored
-
2025A generalist foundation model agent needs to have a large and diverse skill repertoire, such as finding directions between two travel locations and buying specific items from the Internet. If each skill needs to be specified manually through a fixed set of human-annotated instructions, the agent’s skill repertoire will necessarily be limited due to the scalability of human-annotated instructions. In this
-
2025Given a semi-structured knowledge base (SKB), where text documents are interconnected by relations, how can we effectively retrieve relevant information to answer user questions? Retrieval-Augmented Generation (RAG) retrieves documents to assist large language models (LLMs) in question answering; while Graph RAG (GRAG) uses structured knowledge bases as its knowledge source. However, many questions require
-
2025Large language models (LLMs) encode vast amounts of world knowledge acquired via training on large web-scale datasets crawled from the internet. However, the datasets used to train the LLMs typically exhibit a geographical bias towards English-speaking Western countries. This results in LLMs producing biased or hallucinated responses to queries that require answers localized to other geographical regions
Academia
View allWhether you're a faculty member or student, there are number of ways you can engage with Amazon.
View all

Gretchen Ertl
The program offers unrestricted funds and other resources to support research at academic institutions and non-profit organizations in areas that align with our mission.
A global university competition to drive secure innovation in generative AI technology, which focuses on responsible AI and large language model coding security.

Credit: Wolfram Scheible
We partner with particular academic organizations across the world for deep and sustained collaborations in multiple research areas of mutual interest.

Courtesy of Pai-Ling Yin
We hire world-class academics to work on large-scale technical challenges, while they continue to teach and conduct research at their universities.
