
From reimagining storage to serverless computing, Aurora continues to push the boundaries of what's possible in database technology.

Amazon VP and distinguished scientist Byron Cook explains how AWS's new Automated Reasoning checks address key challenges in automated reasoning: translating natural to structured language, defining truth, and definitive reasoning.

Trained on millions of hours of data from Amazon fulfillment centers and sortation centers, Amazon’s new DeepFleet models predict future traffic patterns for fleets of mobile robots.

A new philosophy for developing LLM architectures reduces energy requirements, speeds up runtime, and preserves pretrained-model performance.
Customer-obsessed science


Research areas













-
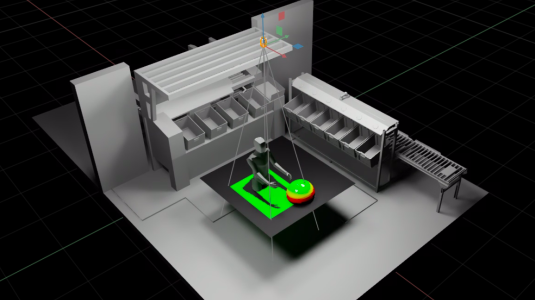
 August 26, 2025With a novel parallel-computing architecture, a CAD-to-USD pipeline, and the use of OpenUSD as ground truth, a new simulator can explore hundreds of sensor configurations in the time it takes to test just a few physical setups.
August 26, 2025With a novel parallel-computing architecture, a CAD-to-USD pipeline, and the use of OpenUSD as ground truth, a new simulator can explore hundreds of sensor configurations in the time it takes to test just a few physical setups.




Featured news

University teams battle to harden and hack AI coding assistants in head-to-head tournament

David Chang/Getty Images/iStockphoto
Led by David Luan and Pieter Abbeel, the lab will focus on developing new foundational capabilities for enabling useful AI agents.

The company's new state-of-the-art foundation models deliver frontier intelligence and industry-leading price performance.
-
2024Multi-document summarization (MDS) is a challenging task, often decomposed to subtasks of salience and redundancy detection, followed by text generation. In this context, alignment of corresponding sentences between a reference summary and its source documents has been leveraged to generate training data for some of the component tasks. Yet, this enabling alignment step has usually been applied heuristically
-
2024Multimodal Large Language Models (MLLMs) excel at synthesizing key information from diverse sources. However, generating accurate and faithful multimodal summaries is challenging, primarily due to the lack of appropriate multimodal datasets for fine-tuning that meaningfully integrate textual and visual modalities. To address this gap, we present a new dataset specifically designed for image-text multimodal
-
2024End-to-end neural diarization (EEND) models offer significant improvements over traditional embedding-based Speaker Diarization (SD) approaches but falls short on generalizing to long-form audio with large number of speakers. EEND-vector-clustering method mitigates this by combining local EEND with global clustering of speaker embeddings from local windows, but this requires an additional speaker embedding
-
SAT 20242024Quantum Computing (QC) is a new computational paradigm that promises significant speedup over classical computing in various domains. However, near-term QC faces numerous challenges, including limited qubit connectivity and noisy quantum operations. To address the qubit connectivity constraint, circuit mapping is required for executing quantum circuits on quantum computers. This process involves performing
-
2024Speaker Diarization (SD) systems are typically audio-based and operate independently of the ASR system in traditional speech transcription pipelines and can have speaker errors due to SD and/or ASR reconciliation, especially around speaker turns and regions of speech overlap. To reduce these errors, a Lexical Speaker Error Correction (LSEC), in which an external language model provides lexical information
Academia
View allWhether you're a faculty member or student, there are number of ways you can engage with Amazon.
View all

Gretchen Ertl
The program offers unrestricted funds and other resources to support research at academic institutions and non-profit organizations in areas that align with our mission.

A global university competition to drive secure innovation in generative AI technology, which focuses on responsible AI and large language model coding security.

Credit: Wolfram Scheible
We partner with particular academic organizations across the world for deep and sustained collaborations in multiple research areas of mutual interest.

Courtesy of Pai-Ling Yin
We hire world-class academics to work on large-scale technical challenges, while they continue to teach and conduct research at their universities.
