













Computerized question-answering systems usually take one of two approaches. Either they do a text search and try to infer the semantic relationships between entities named in the text, or they explore a hand-curated knowledge graph, a data structure that directly encodes relationships among entities.
With complex questions, however — such as “Which Nolan films won an Oscar but missed a Golden Globe?” — both of these approaches run into difficulties. Text search would require a single document to contain all of the information required to satisfy the question, which is highly unlikely. But even if the knowledge graph was up to date, it would have to explicitly represent all the connections established by the question, which is also unlikely.
In a paper we presented last week at the ACM’s SIGIR Conference on Research and Development in Information Retrieval, my colleagues and I describe a new approach to answering complex questions that, in tests, demonstrated clear improvements over several competing approaches.
In a way, our technique combines the two standard approaches. On the basis of the input question, we first do a text search, retrieving the 10 or so documents that the search algorithm ranks highest. Then, on the fly, we construct a knowledge graph that integrates data distributed across the documents.
Because that knowledge graph is produced algorithmically — not carefully curated, the way most knowledge graphs are — it includes a lot of noise, or spurious inferred relationships. We choose to err on the side of completeness, ensuring that our graph represents most of the relationships described in a text, even at the cost of a lot of noise. Then we rely on clever algorithms to filter out the noise when constructing a response to a question.
In evaluating our approach, we used two different types of baselines: an alternative system and alternative algorithms. The alternative system was a state-of-the-art neural network that learns to answer questions from a large body of training data. The alternative algorithms were state-of-the-art graph search algorithms, which we applied to our ad hoc knowledge graph.
In 36 tests using two different data sets and three different performance metrics, our system outperformed all three baselines on 34, finishing a close second on the other two. The average improvement over the best-performing baseline was 25%, with a high of 80%.
Our system begins with an ordinary web search, using the full text of the question as a search string. In our experiments, we used several different search engines, to ensure that search engine quality doesn’t bias the results. We retrieve the ten top-ranked documents and use standard algorithms to identify named entities and parts of speech within each.
Then we use an information extraction algorithm of our own devising to extract subject-predicate-object triples from the text. Predicates are established either by verbs — as in the triple <Nolan, directed, Inception> — or prepositions — as in <The Social Network, winner of, Best Screenplay>. We also assign each triple a confidence score, based on how close to each other the words are in the text.
Then, from all the triples extracted from all the documents, we assemble a graph.
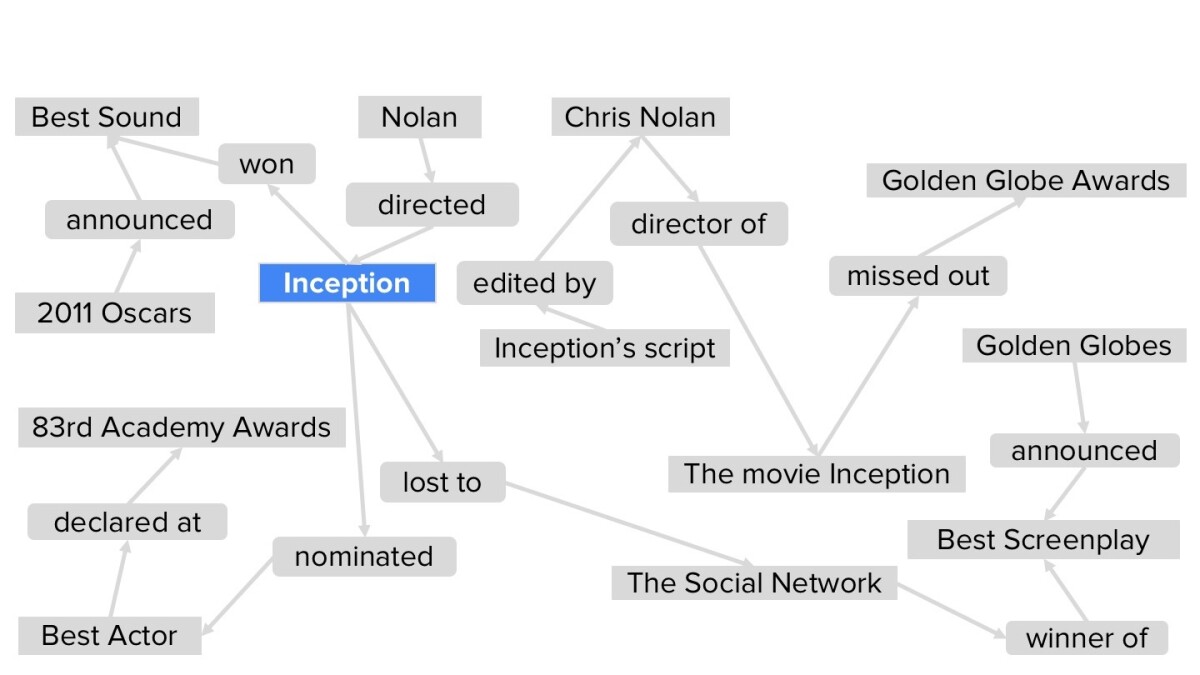
Using syntactic clues — such as “A and other X’s” or “X’s such as A” — and data from existing knowledge graphs, we then add nodes to our graph that indicate the types of the named entities. We also use existing lexicons and embeddings, which capture information about words’ meanings, to decide which names in the graph refer to the same entities. Like the relationships encoded in the data triples, the name alignments are assigned confidence scores.
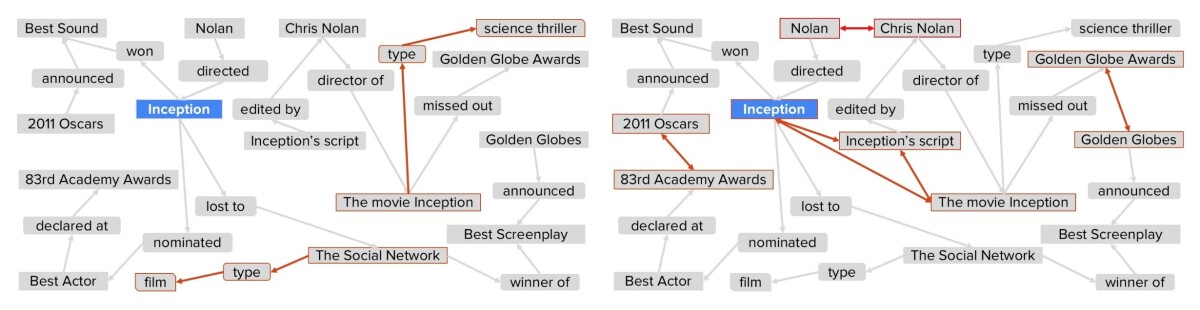
The graph itself is now complete. Our search algorithm’s first step is to identify cornerstones in the graph. These are words that very closely match individual words in the search string.
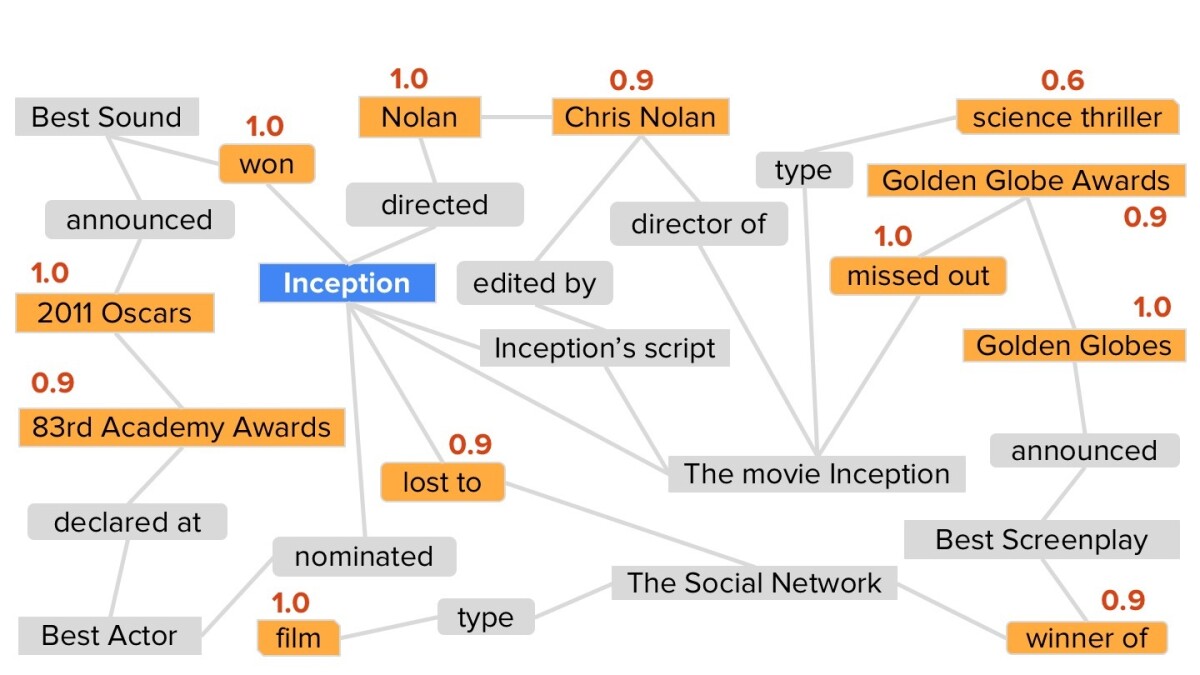
Our assumption is that the answers to questions lie on paths connecting cornerstones. Each path through the graph is evaluated according to two criteria: its length (shorter paths are better) and its weights (the confidence scores from the data triples and the name alignments). We then eliminate all but the shortest, highest-confidence paths.
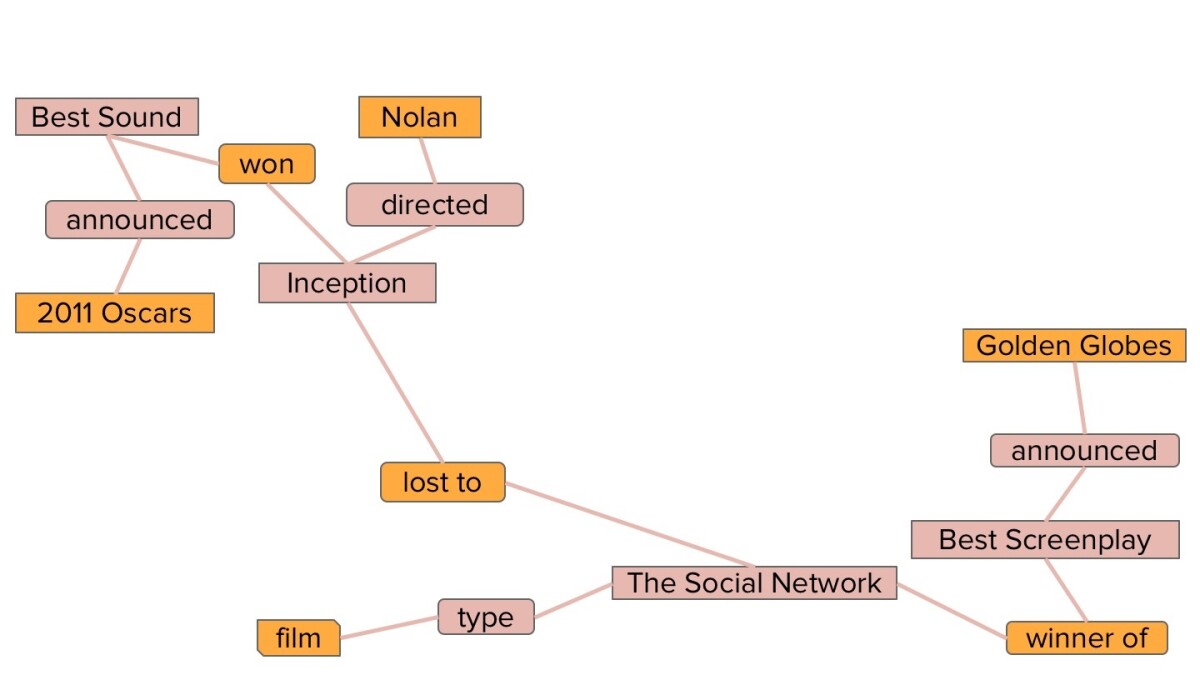
Next, we remove all the cornerstones from the graph, on the assumption that they can’t be answers to the question, along with all the nodes that are not named entities.
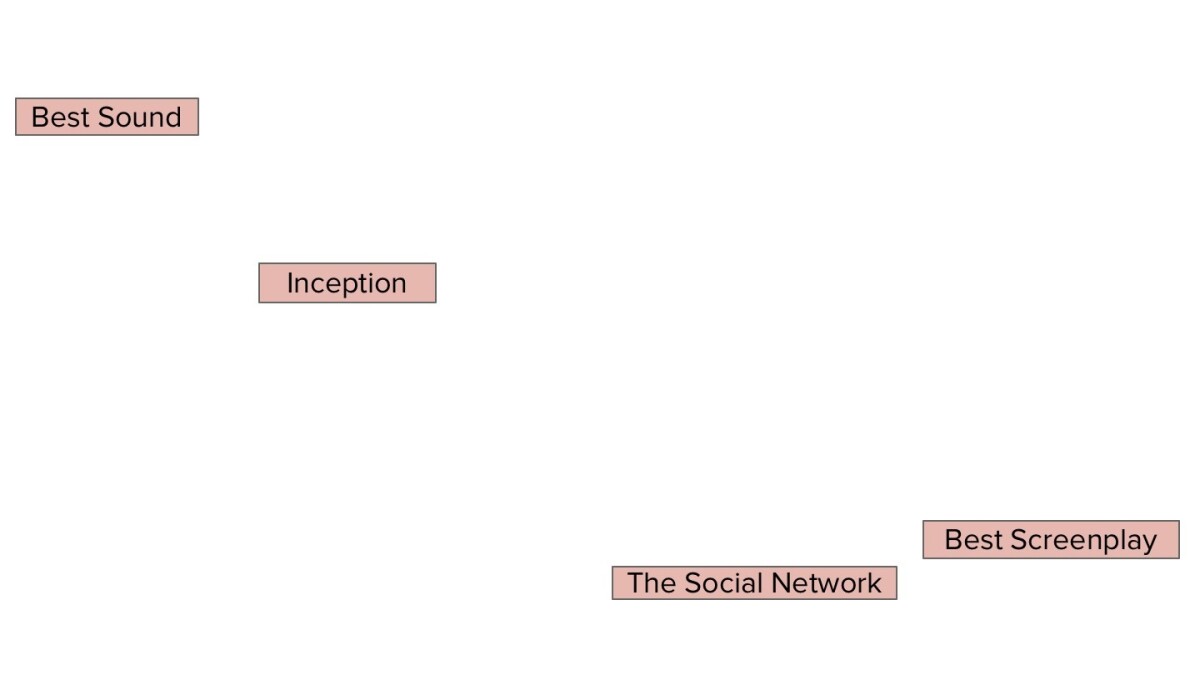
From the initial query, an algorithm that we reported previously predicts the lexical type of the answer. If the question begins “Which films won … ”, for instance, the algorithm will predict that the answer to the question should be of the type “film”. We then excise all entities that do not match the predicted type. In this case, that leaves us with two entities: Inception and The Social Network.
Finally, our algorithm ranks the remaining entities according to several criteria, such as the weights of the paths that connect them to cornerstones, their distance from cornerstones, the number of paths through the network that lead through them, and so on. In this case, that leaves us with one entity, Inception, which the algorithm returns as the answer to the search question.
Although our system significantly outperforms state-of-the-art baselines, there is still room for improvement. One avenue of future research that we consider promising is the integration of the ad hoc knowledge graphs with existing, curated knowledge graphs and the adaptation of the search algorithm accordingly.
Acknowledgments: Xiaolu Lu, Soumajit Pramanik, Rishiraj Saha Roy, Yafang Wang, Gerhard Weikum



