The quantile function is a mathematical function that takes a quantile (a percentage of a distribution, from 0 to 1) as input and outputs the value of a variable. It can answer questions like, “If I want to guarantee that 95% of my customers receive their orders within 24 hours, how much inventory do I need to keep on hand?” As such, the quantile function is commonly used in the context of forecasting questions.
In practical cases, however, we rarely have a tidy formula for computing the quantile function. Instead, statisticians usually use regression analysis to approximate it for a single quantile level at a time. That means that if you decide you want to compute it for a different quantile, you have to build a new regression model — which, today, often means retraining a neural network.
In a pair of papers we’re presenting at this year’s International Conference on Artificial Intelligence and Statistics (AISTATS), we describe an approach to learning an approximation of the entire quantile function at once, rather than simply approximating it for each quantile level.

This means that users can query the function at different points, to optimize the trade-offs between performance criteria. For instance, it could be that lowering the guarantee of 24-hour delivery from 95% to 94% enables a much larger reduction in inventory, which might be a trade-off worth making. Or, conversely, it could be that raising the guarantee threshold — and thus increasing customer satisfaction — requires very little additional inventory.
Our approach is agnostic as to the shape of the distribution underlying the quantile function. The distribution could be Gaussian (the bell curve, or normal distribution); it could be uniform; or it could be anything else. Not locking ourselves into any assumptions about distribution shape allows our approach to follow the data wherever it leads, which increases the accuracy of our approximations.
In the first of our AISTATS papers, we present an approach to learning the quantile function in the univariate case, where there’s a one-to-one correspondence between probabilities and variable values. In the second paper, we consider the multivariate case.
The quantile function
Any probability distribution — say, the distribution of heights in a population — can be represented as a function, called the probability density function (PDF). The input to the function is a variable (a particular height), and the output is a positive number representing the probability of the input (the fraction of people in that population who have that height).

A useful related function is the cumulative distribution function (CDF), which is the probability that the variable will take a value at or below a particular value — for instance, the fraction of the population that is 5’6” or shorter. The CDF’s values are between 0 (no one is shorter than 0’0”) and 1 (100% of the population is shorter than 500’0”).
Technically, the CDF is the integral of the PDF, so it computes the area under the probability curve up to the target point. At low input values, the probability output by the CDF can be lower than that output by the PDF. But because the CDF is cumulative, it is monotonically non-decreasing: the higher the input value, the higher the output value.
If the CDF exists, the quantile function is simply its inverse. The quantile function’s graph can be produced by flipping the CDF graph over — that is, rotating it 180 degrees around a diagonal axis that extends for the lower left to the upper right of the graph.

Like the CDF, the quantile function is monotonically non-decreasing. That’s the fundamental observation on which our method rests.
The univariate case
One of the drawbacks of the conventional approach to approximating the quantile function — estimating it only at specific points — is that it can lead to quantile crossing. That is, because each prediction is based on a different model, trained on different local data, the predicted variable value for a given probability could be lower than the value predicted for a lower probability. This violates the requirement that the quantile function be monotonically non-decreasing.
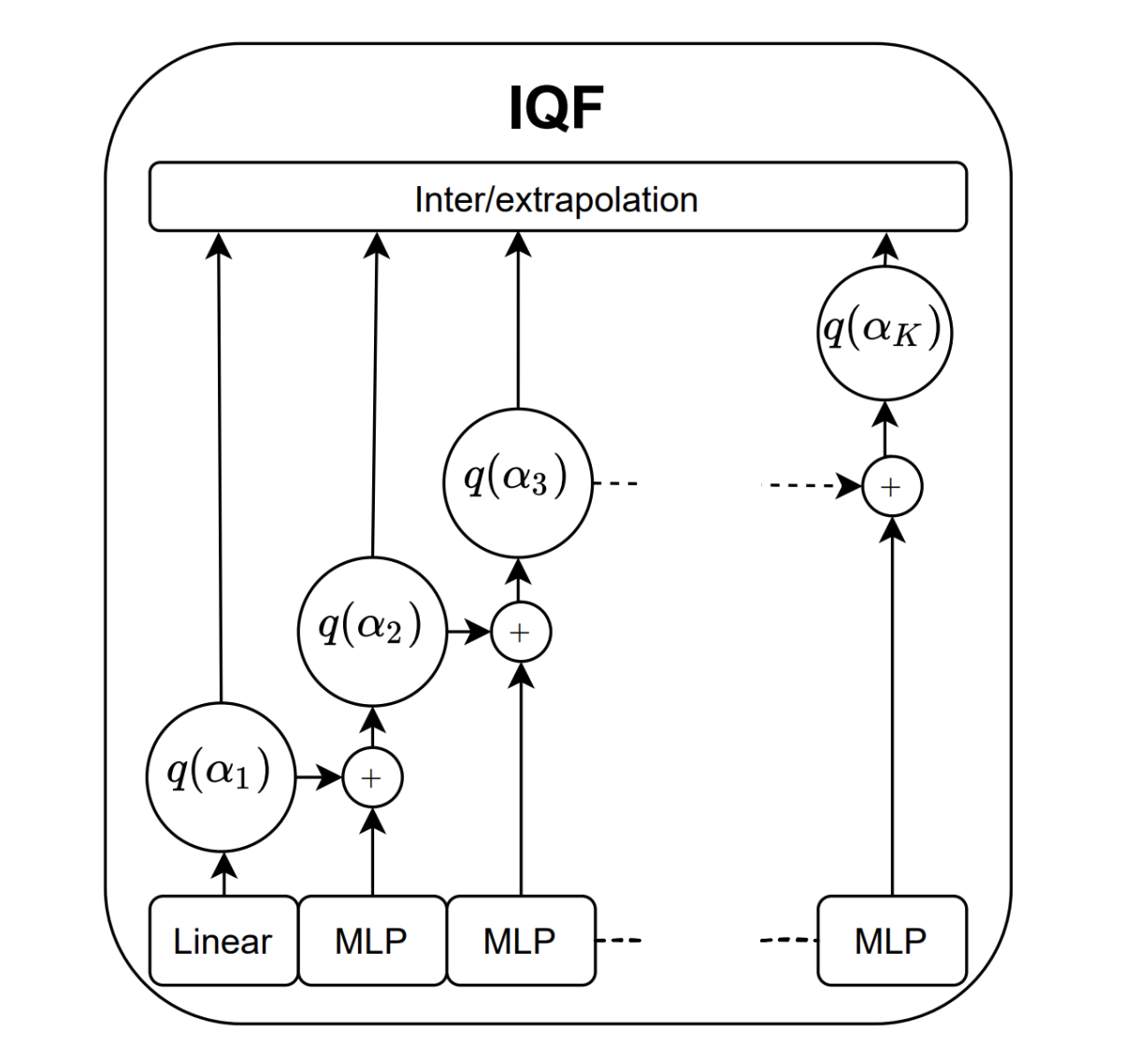
To avoid quantile crossing, our method learns a predictive model for several different input values — quantiles — at once, spaced at regular intervals between 0 and 1. The model is a neural network designed so that the prediction for each successive quantile is an incremental increase of the prediction for the preceding quantile.
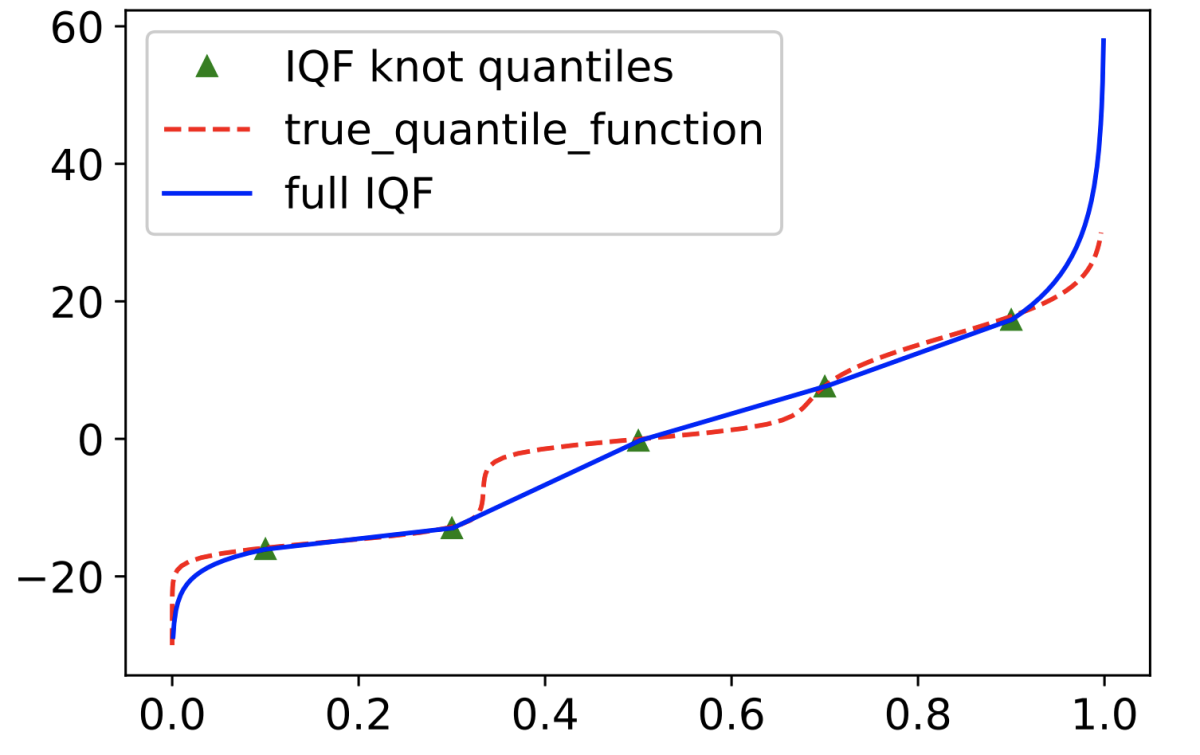
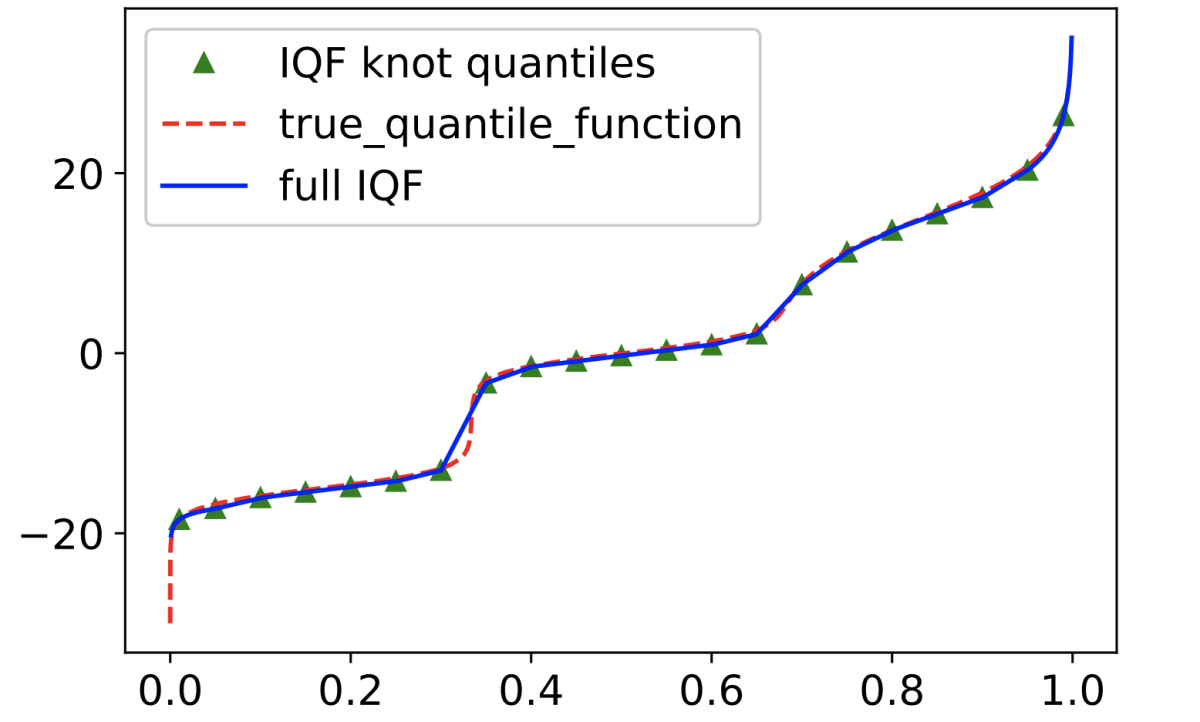
Once our model has learned estimates for several anchor points that enforce the monotonicity of the quantile function, we can estimate the function through simple linear extrapolation between the anchor points (called “knots” in the literature), with nonlinear extrapolation to handle the tails of the function.
Where training data is plentiful enough to enable a denser concentration of anchor points (knots), linear extrapolation provides a more accurate approximation.
To test our method, we applied it to a toy distribution with three arbitrary peaks, to demonstrate that we don’t need to make any assumptions about distribution shape.
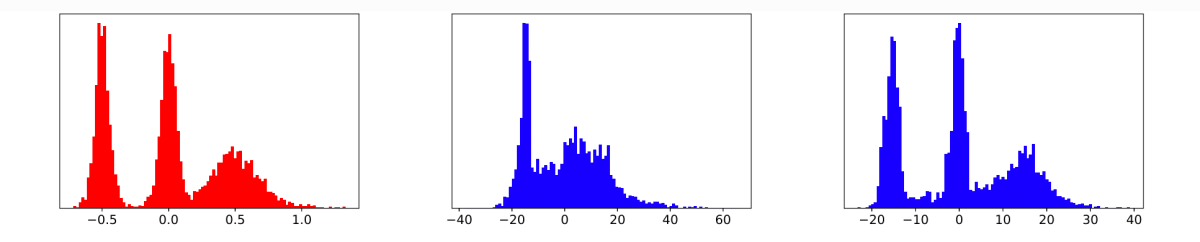
The multivariate case
So far, we’ve been considering the case in which our distribution applies to a single variable. But in many practical forecasting use cases, we want to consider multivariate distributions.
For instance, if a particular product uses a rare battery that doesn’t come included, a forecast of the demand for that battery will probably be correlated with the forecast of the demand for that product.

Similarly, if we want to predict demand over several different time horizons, we would expect there to be some correlation between consecutive predictions: demand shouldn’t undulate too wildly. A multivariate probability distribution over time horizons should capture that correlation better than a separate univariate prediction for each horizon.
The problem is that the notion of a multivariate quantile function is not well defined. If the CDF maps multiple variables to a single probability, when you perform that mapping in reverse, which value do you map to?
This is the problem we address in our second AISTATS paper. Again, the core observation is that the quantile function must be monotonically non-decreasing. So we define the multivariate quantile function as the derivative of a convex function.
A convex function is one that tends everywhere toward a single global minimum: in two dimensions, it looks like a U-shaped curve. The derivative of a function computes the slope of its graph: again in the two-dimensional case, the slope of a convex function is negative but flattening as it approaches the global minimum, zero at the minimum, and increasingly positive on the other side. Hence, the derivative is monotonically increasing.
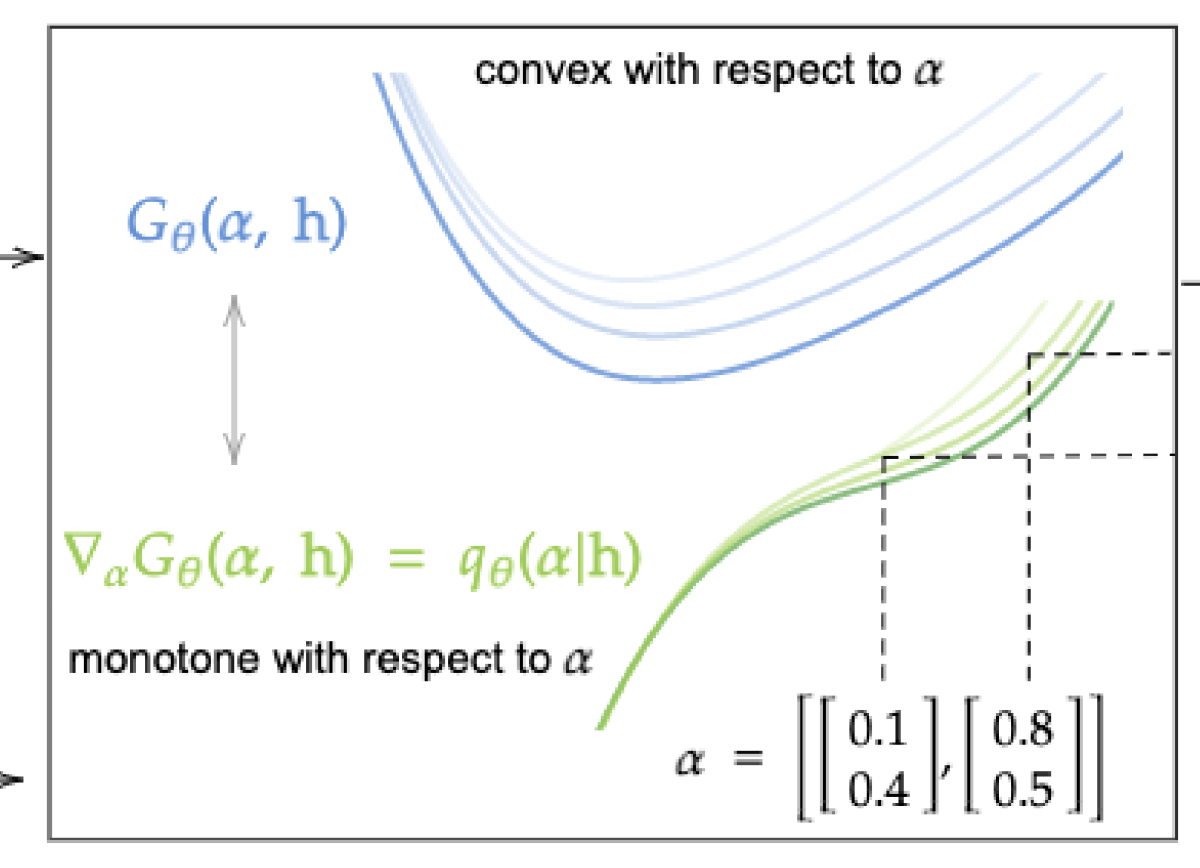
This two-dimensional picture generalizes readily to higher dimensions. In our paper, we describe a method for training a neural network to learn a quantile function that is the derivative of a convex function. The architecture of the network enforces convexity, and, essentially, the model learns the convex function using its derivative as a training signal.
In addition to real-world datasets, we test our approach on the problem of simultaneous prediction across multiple time horizons, using a dataset that follows a multivariate Gaussian distribution. Our experiments showed that, indeed, our approach better captures the correlations between successive time horizons than a univariate approach.
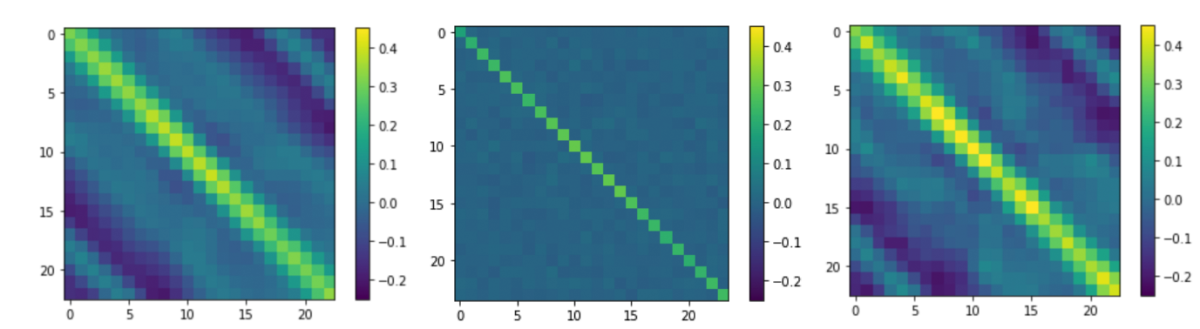
This work continues a line of research at Amazon combining quantile regression and deep learning to solve forecasting problems at a massive scale. In particular, it builds upon work on the MQ-CNN model proposed by a group of Amazon scientists in 2017, extensions of which are currently powering Amazon’s demand forecasting system. The current work is also closely related to spline quantile function RNNs, which — like the multivariate quantile forecaster — started as an internship project.
Code for all these methods is available in the open source GluonTS probabilistic time series modeling library.
Acknowledgements
This work would have not been possible without the help of our awesome co-authors, whom we would like to thank for their contributions to these two papers: Kelvin Kan, Danielle Maddix, Tim Januschowski, Konstantinos Benidis, Lars Ruthotto, and Yuyang Wang, Jan Gasthaus.