
With a novel parallel-computing architecture, a CAD-to-USD pipeline, and the use of OpenUSD as ground truth, a new simulator can explore hundreds of sensor configurations in the time it takes to test just a few physical setups.

From reimagining storage to serverless computing, Aurora continues to push the boundaries of what's possible in database technology.

Amazon VP and distinguished scientist Byron Cook explains how AWS's new Automated Reasoning checks address key challenges in automated reasoning: translating natural to structured language, defining truth, and definitive reasoning.

Trained on millions of hours of data from Amazon fulfillment centers and sortation centers, Amazon’s new DeepFleet models predict future traffic patterns for fleets of mobile robots.
Customer-obsessed science


Research areas













-
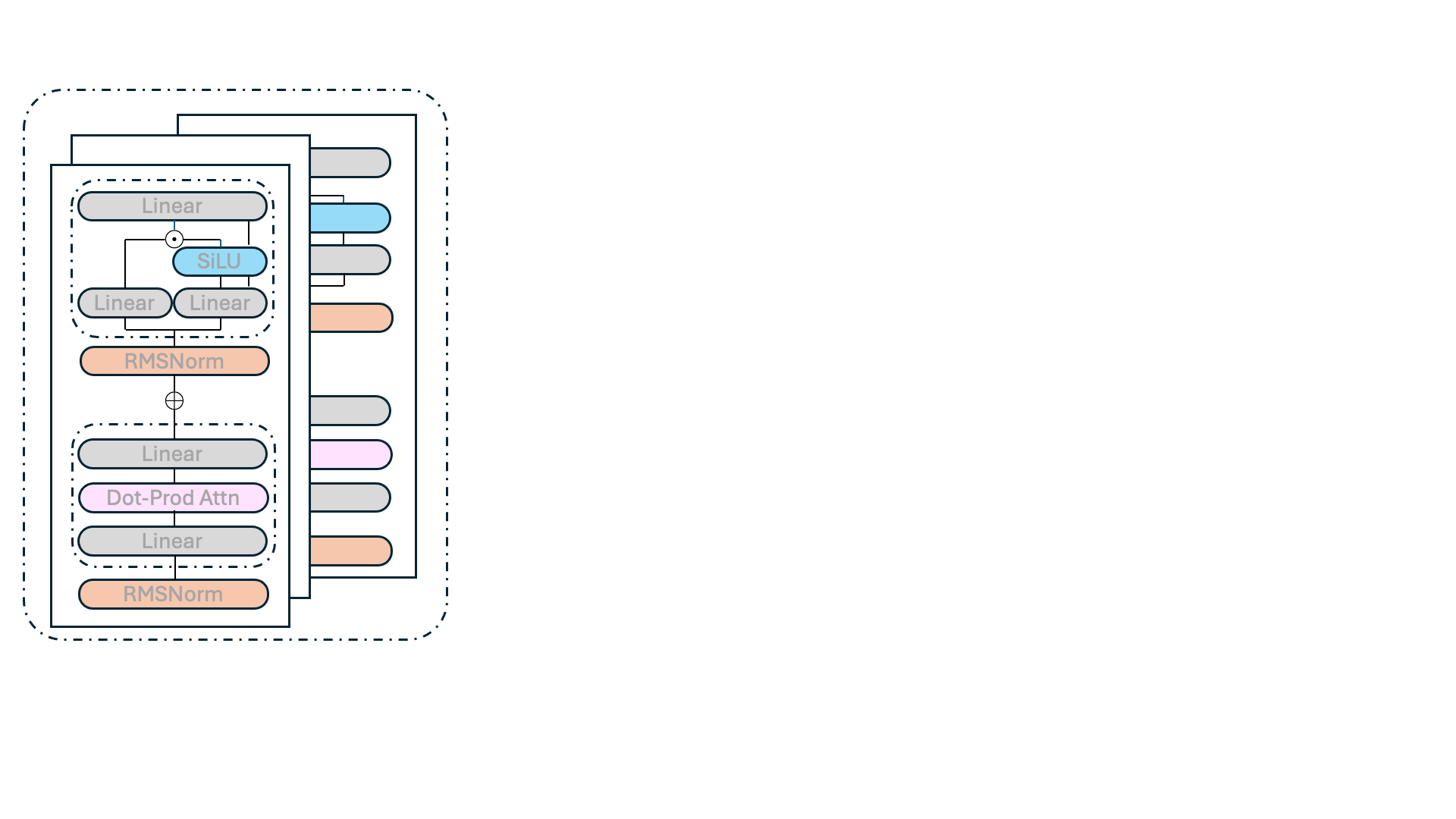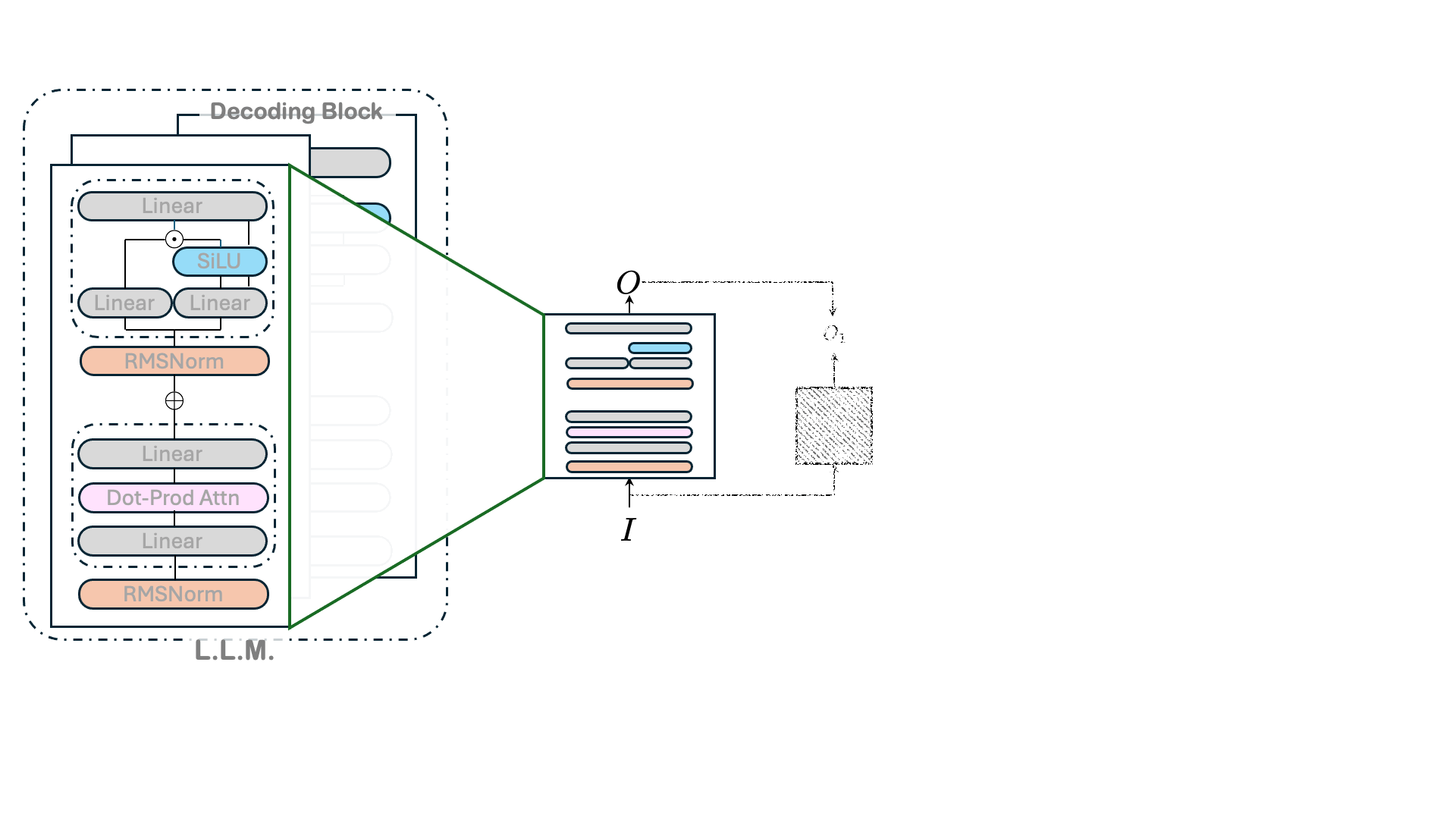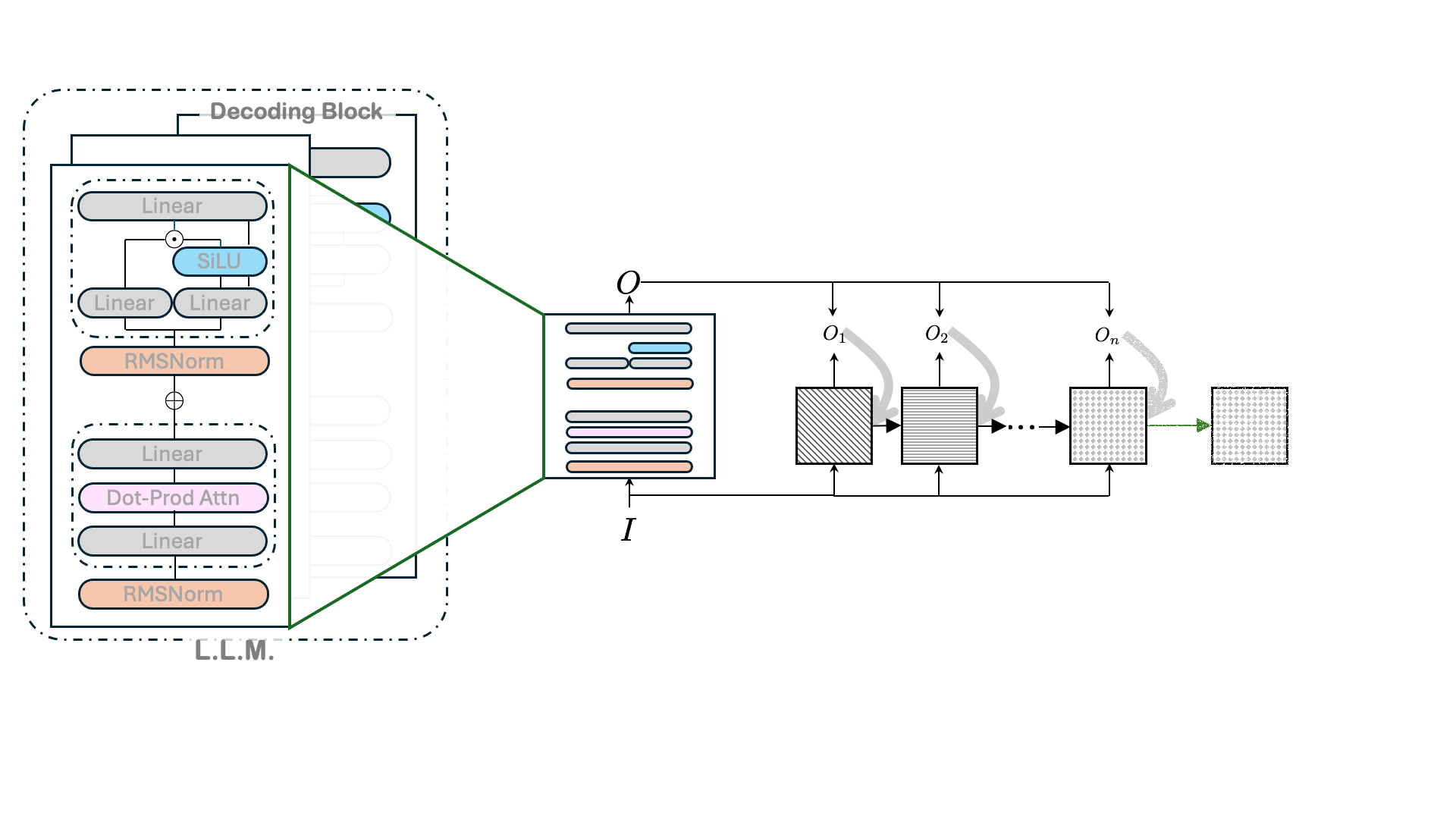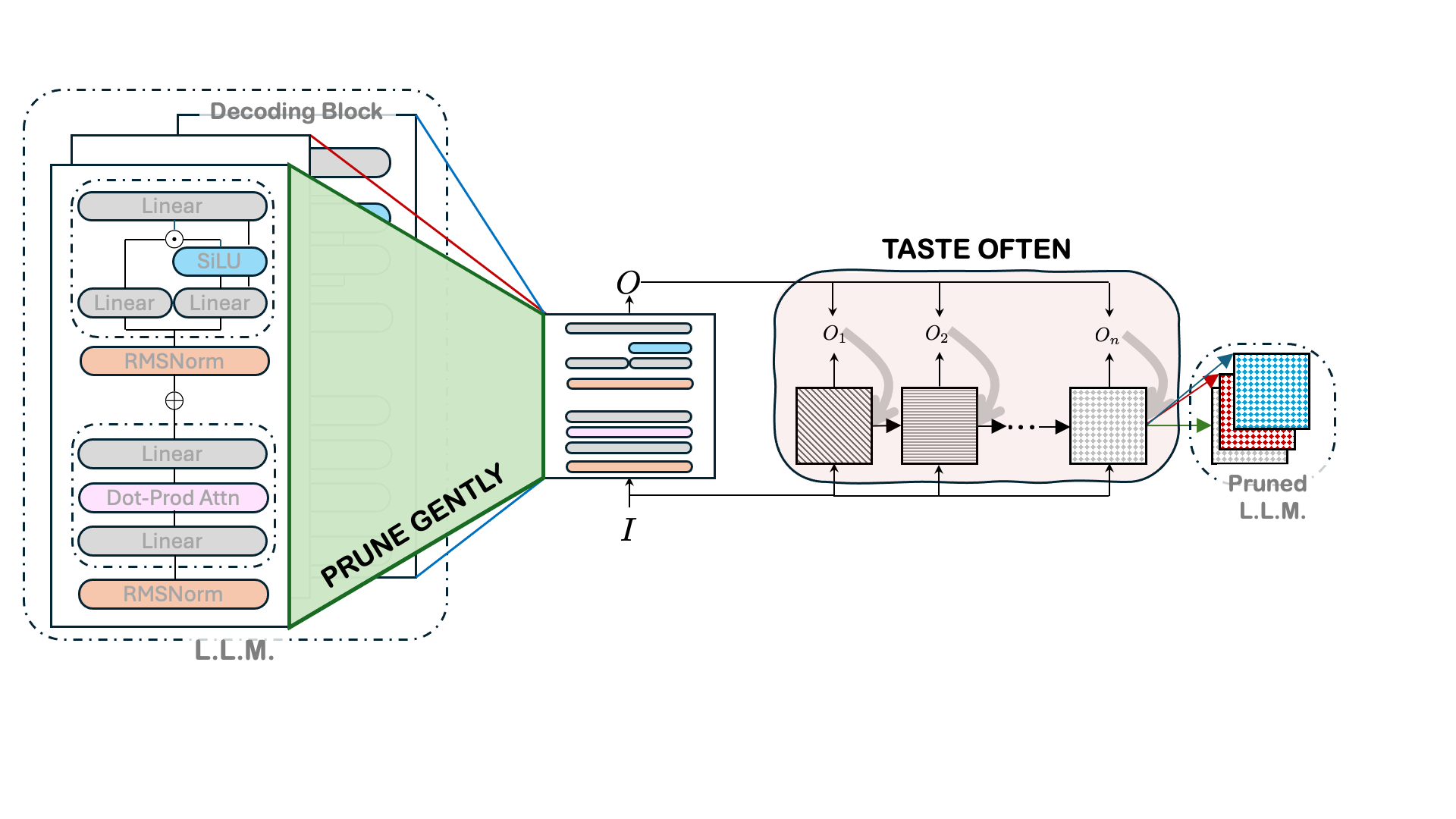
 August 8, 2025A new philosophy for developing LLM architectures reduces energy requirements, speeds up runtime, and preserves pretrained-model performance.
August 8, 2025A new philosophy for developing LLM architectures reduces energy requirements, speeds up runtime, and preserves pretrained-model performance.




Featured news

University teams battle to harden and hack AI coding assistants in head-to-head tournament

David Chang/Getty Images/iStockphoto
Led by David Luan and Pieter Abbeel, the lab will focus on developing new foundational capabilities for enabling useful AI agents.

The company's new state-of-the-art foundation models deliver frontier intelligence and industry-leading price performance.
-
2024 Conference on Digital Experimentation @ MIT (CODE@MIT)2024Many data-driven companies measure the impact of product groups and allocate resources across them based on the estimated impacts of features they launch via A/B tests. In this doc, we show that, when based on a standard frequentist estimator of the impact of features, this practice can significantly overstate the impact of product groups and distort the allocation of resources. When this practice is instead
-
ACM SoCC 20242024Database performance troubleshooting is a complex multi-step process that broadly involves three key stages– (a) Detection: determining what’s wrong and when; (b) Root Cause Analysis (RCA): reasoning about why is the performance poor; (c) Resolution: identifying a fix. A plethora of techniques exist to address each of these problems, but they hardly work in real-world at scale. First, real-world customer
-
Getting a good understanding of the customer intent is essential in e-commerce search engines. In particular, associating the correct product type to a search query plays a vital role in surfacing correct products to the customers. Query product type classification (Q2PT) is a particularly challenging task because search queries are short and ambiguous, the number of existing product categories is extremely
-
2024Training large language models (LLMs) for external tool usage is a rapidly expanding field, with recent research focusing on generating synthetic data to address the shortage of available data. However, the absence of systematic data quality checks poses complications for properly training and testing models. To that end, we propose two approaches for assessing the reliability of data for training LLMs
-
2024Current instruction-tuned language models are exclusively trained with textual preference data and thus are often not aligned with the unique requirements of other modalities, such as speech. To better align language models with the speech domain, we explore (i) prompting strategies grounded in radio-industry best practices and (ii) preference learning using a novel speech-based preference data of 20K samples
Academia
View allWhether you're a faculty member or student, there are number of ways you can engage with Amazon.
View all

Gretchen Ertl
The program offers unrestricted funds and other resources to support research at academic institutions and non-profit organizations in areas that align with our mission.

A global university competition to drive secure innovation in generative AI technology, which focuses on responsible AI and large language model coding security.

Credit: Wolfram Scheible
We partner with particular academic organizations across the world for deep and sustained collaborations in multiple research areas of mutual interest.

Courtesy of Pai-Ling Yin
We hire world-class academics to work on large-scale technical challenges, while they continue to teach and conduct research at their universities.
