
From reimagining storage to serverless computing, Aurora continues to push the boundaries of what's possible in database technology.

Amazon VP and distinguished scientist Byron Cook explains how AWS's new Automated Reasoning checks address key challenges in automated reasoning: translating natural to structured language, defining truth, and definitive reasoning.

Trained on millions of hours of data from Amazon fulfillment centers and sortation centers, Amazon’s new DeepFleet models predict future traffic patterns for fleets of mobile robots.

A new philosophy for developing LLM architectures reduces energy requirements, speeds up runtime, and preserves pretrained-model performance.
Customer-obsessed science


Research areas













-
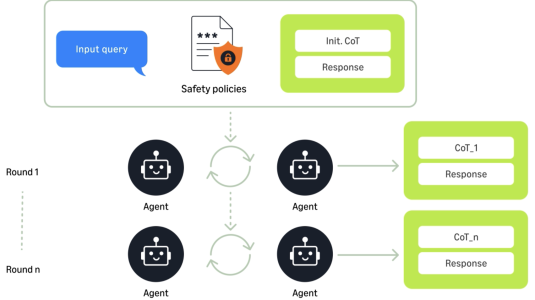
 July 31, 2025Using ensembles of agents to generate and refine interactions annotated with chains of thought improves performance on a battery of benchmarks by an average of 29%.
July 31, 2025Using ensembles of agents to generate and refine interactions annotated with chains of thought improves performance on a battery of benchmarks by an average of 29%.




Featured news

University teams battle to harden and hack AI coding assistants in head-to-head tournament

David Chang/Getty Images/iStockphoto
Led by David Luan and Pieter Abbeel, the lab will focus on developing new foundational capabilities for enabling useful AI agents.

The company's new state-of-the-art foundation models deliver frontier intelligence and industry-leading price performance.
-
Machine Learning for Healthcare 20242024Given a particular claim about a specific document, the fact checking problem is to determine if the claim is true and, if so, provide corroborating evidence. The problem is motivated by contexts where a document is too lengthy to quickly read and find an answer. This paper focuses on electronic health records, or a medical dossier, where a physician has a pointed claim to make about the record. Prior methods
-
2024We present Event-focused Search, an automated and scalable pipeline designed to facilitate event discovery and enhance event-based search. This is done by leveraging large language models (LLMs) to populate event datasets, perform temporal search based on selected dates, and aggregate search results based on appropriate events based on those searches. We illustrate this pipeline through proof-of-concept
-
2024NeurAlly-Decomposed Oracle (NADO) is a powerful approach for controllable generation with large language models. It is designed to avoid catastrophic forgetting while achieving guaranteed convergence to an entropy-maximized closed-form optimal solution with reasonable modeling capacity. Despite the success, several challenges arise when apply NADO to a wide range of scenarios. Vanilla NADO suffers from
-
Affordance grounding refers to the task of finding the area of an object with which one can interact. It is a fundamental but challenging task, as a successful solution requires the comprehensive understanding of a scene in multiple aspects including detection, localization, and recognition of objects with their parts, of geospatial configuration/layout of the scene, of 3D shapes and physics, as well as
-
Large Language Models (LLMs) can be leveraged to improve performance in various stages of the search pipeline – the indexing stage, the query understanding stage, and the ranking or re-ranking stage. The latter two stages involve invoking a LLM during inference, adding latency in fetching the final ranked list of documents. Index enhancement, on the other hand, can be done in the indexing stage, in near
Academia
View allWhether you're a faculty member or student, there are number of ways you can engage with Amazon.
View all

Gretchen Ertl
The program offers unrestricted funds and other resources to support research at academic institutions and non-profit organizations in areas that align with our mission.

A global university competition to drive secure innovation in generative AI technology, which focuses on responsible AI and large language model coding security.

Credit: Wolfram Scheible
We partner with particular academic organizations across the world for deep and sustained collaborations in multiple research areas of mutual interest.

Courtesy of Pai-Ling Yin
We hire world-class academics to work on large-scale technical challenges, while they continue to teach and conduct research at their universities.
