
Conversational-AI systems have traditionally fallen into two categories: goal-oriented systems, which help users fulfill requests, and chatbots, which carry on informative or entertaining conversations.
Recently, the two areas have begun to converge, but separately or together, they both benefit from accurate “topic modeling”. Identifying the topic of a particular utterance can help goal-oriented systems route requests more accurately and keep chatbots’ comments relevant and engaging. Accurate topic tracking has also been shown to be strongly correlated with users’ subjective assessments of the quality of chatbot conversations.
In a paper we’re presenting at this year’s IEEE Spoken Language Technologies conference, we describe a system that uses two additional sources of information to determine the topic of a given utterance: the utterances that immediately preceded it and its classification as a “dialogue act”. Factoring that information in improves the accuracy of the system’s topic classification by 35%.
We validated our approach using more than 100,000 annotated utterances collected during the 2017 Alexa Prize competition, in which 15 academic research teams deployed experimental Alexa chatbot systems. In addition to generating innovative ideas about system design, the Alexa Prize helps address the chicken-and-egg problem that plagues conversational AI: training quality chatbots depends on realistic interaction data, but realistic interaction data is hard to come by without chatbots that people want to talk to.
Over the years, conversational-AI researchers have developed some standard taxonomies for classifying utterances as dialogue acts such as InformationRequests, Clarifications, or UserInstructions. Dialogue management systems generally use such classifications to track the progress of conversations.
We asked a team of annotators to label the data in our training set according to 14 dialogue acts and 12 topics, such as Politics, Fashion, EntertainmentMovies, and EntertainmentBooks. We also asked them to identify keywords in the utterances that helped them determine topics. For instance, a chatbot’s declaration that “Gucci is a famous brand from Italy” was assigned the topic Fashion, and “Gucci”, “brand”, and “Italy” were tagged as keywords associated with that topic.
We built topic-modeling systems that used three different neural-network architectures. One was a simple but fast network called a deep averaging network, or DAN. Another was a variation on the DAN that learned to predict not only the topics of utterances but also the keywords that indicated those topics. The third was a more sophisticated network called a bidirectional long-short-term-memory network.
Long short-term memory (LSTM) networks process sequential data — such as strings of spoken words — in order, and a given output factors in the outputs that preceded it. LSTMs are widely used in natural-language understanding: the interpretation of the fifth word in a sentence, for instance, will often depend on interpretations of the first four. A bidirectional LSTM (bi-LSTM) network is one that runs through the same data sequence both forward and backward.
Inputs to all three networks consist of a given utterance, its dialogue act classification, and it conversational context. Here, context means the last five turns of conversation, where a turn is a combination of a speaker utterance and a chatbot response. The dialogue act classifications come from a separate DAN model, which we trained using our labeled data.
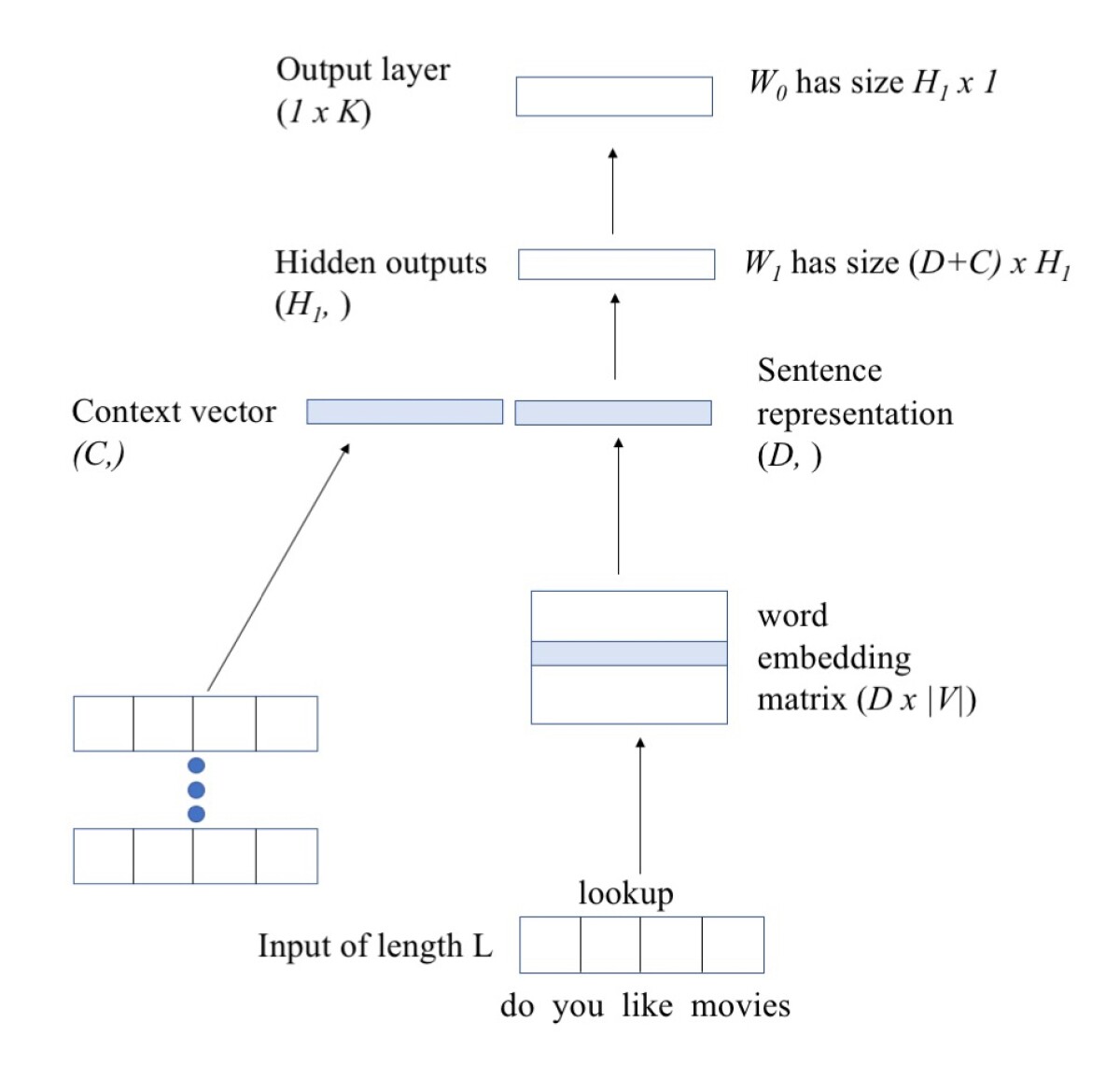
In the DAN-based topic-modeling system, the first step is to embed the words of the input utterances, both the current utterance and the prior turns of conversation. An embedding is a representation of a word as a point in a high-dimensional space, such that words with similar meanings are grouped together. The DAN produces embeddings of full sentences by simply averaging the embeddings of their words.
The embeddings of the prior turns of conversation are then averaged with each other to produce a single summary embedding, which is appended to the embedding of the current utterance. The combined embedding then passes to a neural network, which learns to correlate embeddings with topic classifications.
The second system, which uses a modified DAN — or ADAN, for attentional DAN — adds several ingredients to this recipe. During training, the ADAN built a matrix that mapped every word it encountered against each of the 12 topics it was being asked to recognize, recording the frequency with which annotators correlated a particular word with a particular topic. Each word thus had 12 numbers associated with it — a 12-dimensional vector — indicating its relevance to each topic. This matrix, which we call a topic-word attention table, gives the ADAN its name.
During operation, the ADAN embeds the words of the current utterance and the past utterances. Like the DAN, it averages the words of the past utterances, then averages the averages together. But it processes the words of the current utterance separately, adding to the embedding of each the corresponding 12-dimensional topic vector. Each of these combination vectors is also combined with the past-utterance summaries, before passing to the neural network for classification.
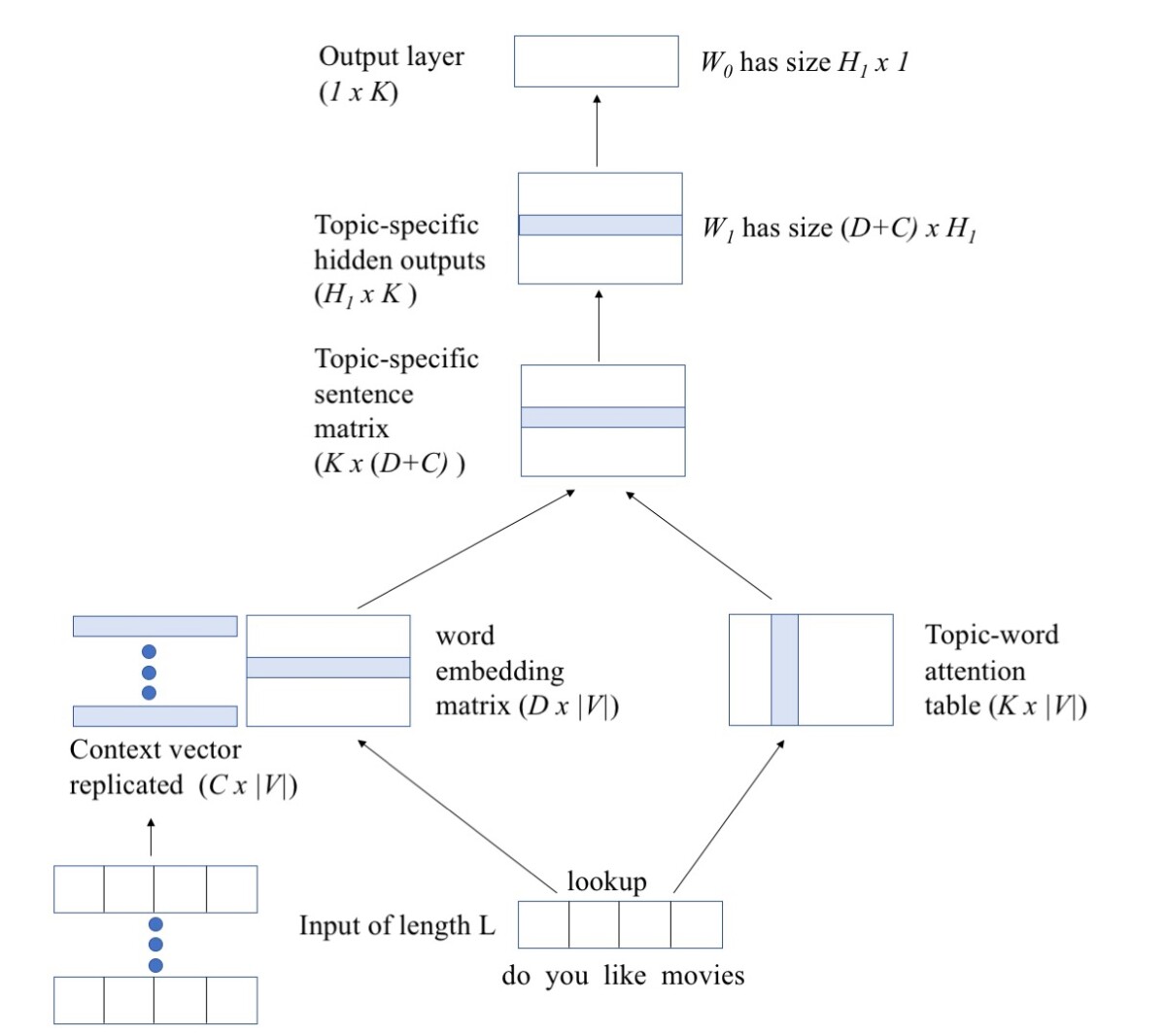
The output of the neural network, however, includes not only a prediction of the topic label but also a prediction of which words in the input correspond to that label. Although such keywords were labeled in our data set, we used the labels only to gauge the system’s performance, not to train it. That is, it learned to identify keywords in an unsupervised way.
Because it can identify keywords, the ADAN, unlike the DAN and the bi-LSTM, is “interpretable”: it issues not only a judgment but also an explanation of the basis for that judgment.
We experimented with two different methods of feeding data about prior utterances to the bi-LSTM. With one method, we fed it an averaged embedding of all five prior turns; in the other, we fed it embeddings of the prior turns sequentially. The first method is more efficient, but the second proved to be more accurate.
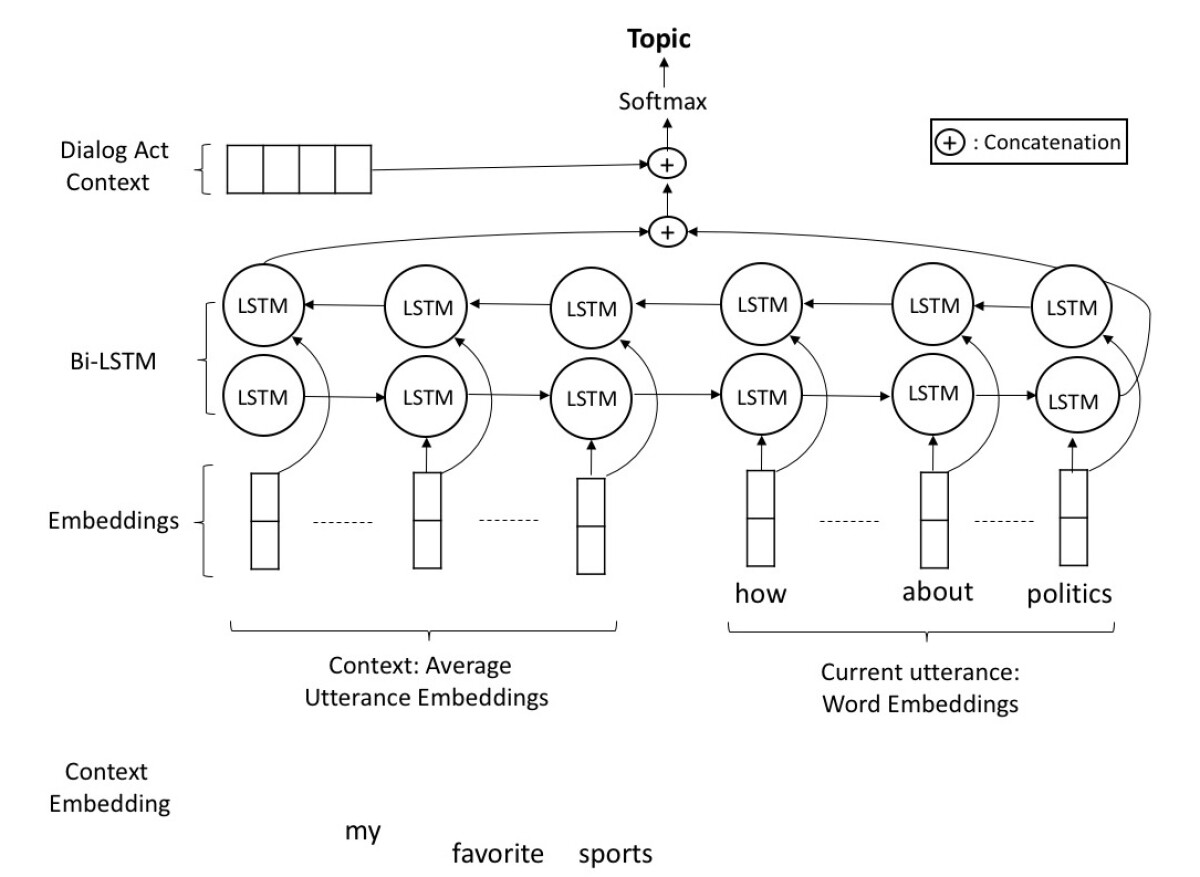
We evaluated four different versions of each system: a baseline version, which used only information about the current utterance; a version that added in only prior-turn information; a version that added in only dialogue act information; and a version that added in both.
With all four systems — DAN, ADAN, and the two varieties of bi-LSTM — adding prior-turn information and dialogue act information, both separately and together, improved accuracy over baseline. The bi-LSTM system augmented with both dialogue act and prior-turn information performed best, with an accuracy of 74 percent, up from 55 percent for baseline.
The ADAN had the lowest accuracy scores, but we suspect that its decision model was too complex to learn accurate correlations from the amount of training data we had available. Its performance should improve with more data, and as dialogue systems grow more sophisticated, interpretability may prove increasingly important.
Acknowledgments: Chandra Khatri, Rahul Goel, Angeliki Metanillou, Anushree Venkatesh, Raefer Gabriel, Arindam Mandal



