Differential privacy is a popular technique that provides a way to quantify the privacy risk of releasing aggregate statistics based on individual data. In the context of machine learning, differential privacy provides a way to protect privacy by adding noise to the data used to train a machine learning model. But the addition of noise can also reduce model performance.
In a pair of papers at the annual meeting of the Florida Artificial Intelligence Research Society (FLAIRS), the Privacy Engineering for Alexa team is presenting a new way to calibrate the noise added to the textual data used to train natural-language-processing (NLP) models. The idea is to distinguish cases where a little noise is enough to protect privacy from cases where more noise is necessary. This helps minimize the impact on model accuracy while maintaining privacy guarantees, which aligns with the team’s mission to measurably preserve customer privacy across Alexa.
One of the papers, “Density-aware differentially private textual perturbations using truncated Gumbel noise”, has won the conference’s best-paper award.

Differential privacy says that, given an aggregate statistic, the probability that the underlying dataset does or does not contain a particular item should be virtually the same. The addition of noise to the data helps enforce that standard, but it can also obscure relationships in the data that the model is trying to learn.
In NLP applications, a standard way to add noise involves embedding the words of the training texts. An embedding represents words as vectors, such that vectors that are close in the space have related meanings.
Adding noise to an embedding vector produces a new vector, which would correspond to a similar but different word. Ideally, substituting the new words for the old should disguise the original data while preserving the attributes that the NLP model is trying to learn.
However, words in an embedding space tend to form clusters, united by semantic similarity, with sparsely populated regions between clusters. Intuitively, within a cluster, much less noise should be required to ensure enough semantic distance to preserve privacy. However, if the noise added to each word is based on the average distance between embeddings — factoring in the sparser regions — it may be more than is necessary for words in dense regions.
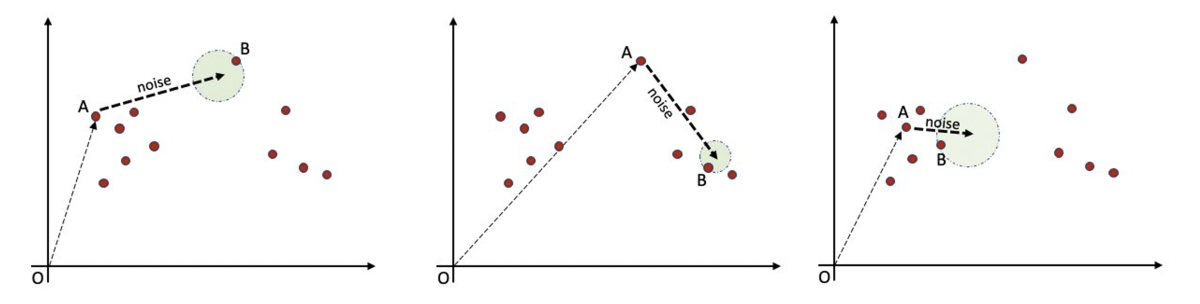
This leads us to pose the following question in our FLAIRS papers: Can we recalibrate the noise added such that it varies for every word depending on the density of the surrounding space, rather than resorting to a single global sensitivity?
Calibration techniques
We study this question from two different perspectives. In the paper titled “Research challenges in designing differentially private text generation mechanisms”, my Alexa colleagues Oluwaseyi Feyisetan, Zekun Xu, Nathanael Teissier, and I discuss general techniques to enhance the privacy of text mechanisms by exploiting features such as local density in the embedding space.
For example, one technique deduces a probability distribution (a prior) that assigns high probability to dense areas of the embedding and low probability to sparse areas. This prior can be produced using kernel density estimation, which is a popular technique for estimating distributions from limited data samples.
However, these distributions are often highly nonlinear, which makes them difficult to sample from. In this case, we can either opt for an approximation to the distribution or adopt indirect sampling strategies such as the Metropolis–Hastings algorithm (which is based on well-known Monte Carlo Markov chain techniques).
Another technique we discuss is to impose a limit on how far away a noisy embedding may be from its source. We explore two ways to do this: distance-based truncation and k-nearest-neighbor-based truncation.
Distance-based truncation simply caps the distance between the noisy embedding and its source, according to some measure of distance in the space. This prevents the addition of a large amount of noise, which is useful in the dense regions of the embedding. But in the sparse regions, this can effectively mean zero perturbation, since there may not be another word within the distance limit.
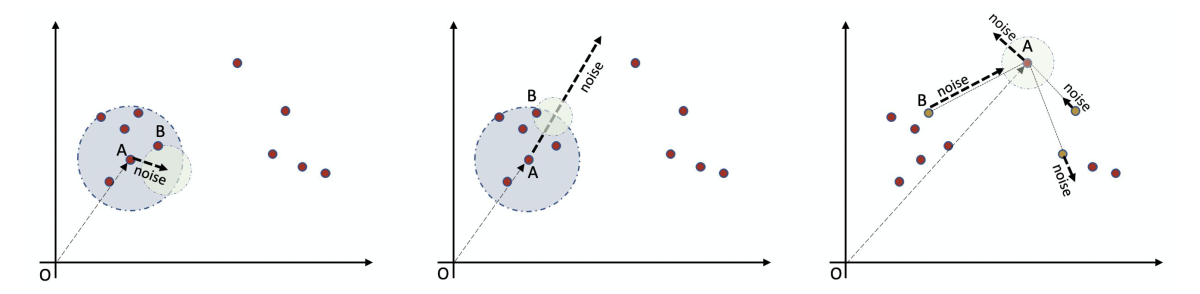
To avoid this drawback, we consider the alternate approach of k-nearest-neighbor-based truncation. In this approach, the k words closest to the source delineate the acceptable search area. We then execute a selection procedure to choose the new word from these k candidates (plus the source word itself). This is the approach we adopt in our second paper.
In “Density-aware differentially private textual perturbations using truncated Gumbel noise”, Nan Xu, a summer intern with our group in 2020 and currently a PhD student in computer science at the University of Southern California, joins us to discuss a particular algorithm in detail.
This algorithm calibrates noise by selecting a few neighbors of the source word and perturbing the distance to these neighbors using samples from the Gumbel distribution (the rightmost graph, above). We chose the Gumbel distribution because it is more computationally efficient than existing mechanisms for differentially private selection (e.g., the exponential mechanism). The number of neighbors is chosen randomly using Poisson samples.
Together, these two techniques, when calibrated appropriately, provide the required amount of differential privacy while enhancing utility. We call the resulting algorithm the truncated Gumbel mechanism, and it better preserves semantic meanings than multivariate Laplace mechanisms, a widely used method for adding noise to textual data. (The left and middle graphs of the top figure above depict the use of Laplace mechanisms).
In tests, we found that this new algorithm provided improvements in accuracy of up to 9.9% for text classification tasks on two different datasets. Our paper also includes a formal proof of the privacy guarantees offered by this mechanism and analyzes relevant privacy statistics.
Our ongoing research efforts continue to improve upon the techniques described above and enable Alexa to continue introducing new features and inventions that make customers’ lives easier while keeping their data private.