
The Amazon Echo is a hands-free smart home speaker you control with your voice. The first important step in enabling a delightful customer experience with an Echo or other Alexa-enabled device is wake word detection, so accurate detection of “Alexa” or substitute wake words is critical. It is challenging to build a wake word system with low error rates when there are limited computation resources on the device and it's in the presence of background noise such as speech or music.
Next week, at the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) 2018, we are presenting two new techniques that improve on-device wake word detection performance:
- A new deep neural network (DNN) architecture for training a speech feature directly from raw audio input; and
- A novel background noise modeling method using monophone-based sound units that can take richer information into account.
In the first paper, we focus on improving the DNN-Hidden Markov Model (HMM) system by training a feature extraction DNN from raw audio rather than handcrafting a speech feature traditionally used in speech recognition. In the second paper, we present a new wake word system that comprises a two-stage classifier and show how wake word performance can be improved by incorporating richer phone (classes of sound) contexts into the two-stage system.
Time Delayed Bottleneck Highway Networks
The illustration below contrasts a conventional DNN architecture to our new DNN structure. A main difference between the two is that our new system replaces a handcrafted log-mel filter bank energy (LFBE) front-end with a trainable front-end DNN. By directly modeling raw audio rather than LFBE, we can learn novel features of the target wake word and optimize our classifier for improved performance. Except for the discrete Fourier transform (DFT), this approach is wholly data-driven. We apply the highway network to direct audio modeling to alleviate the hard optimization problem caused by a deep network structure. Furthermore, we efficiently reduce the large dimension of an input vector with a bottleneck layer followed by a time-delayed window.

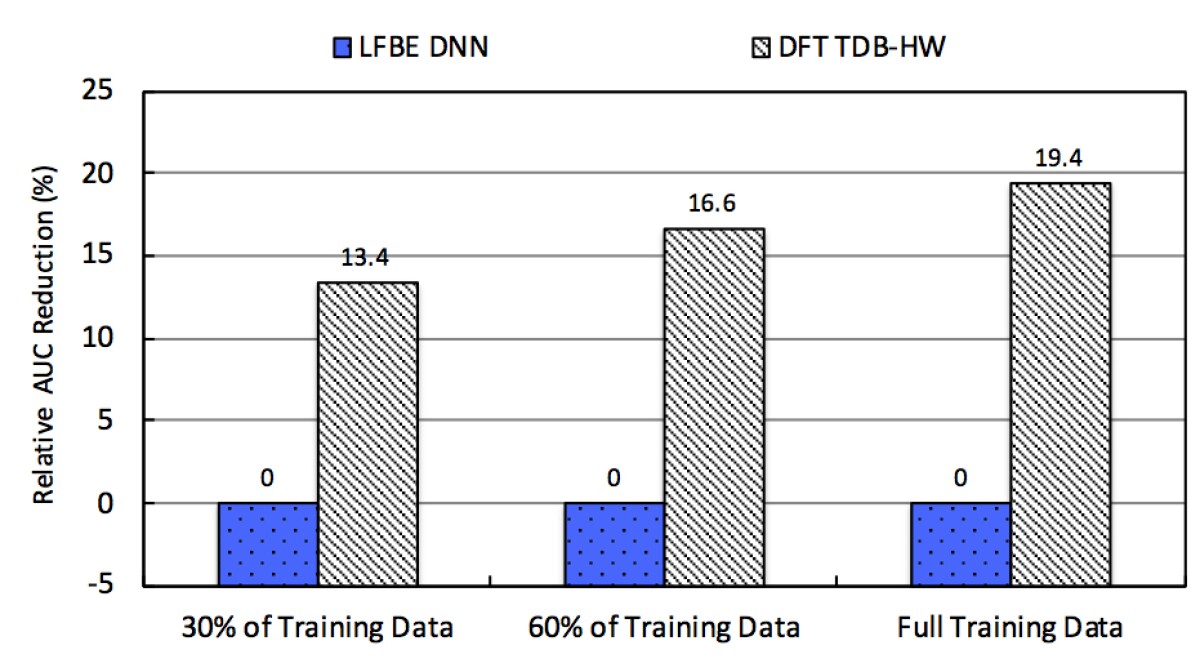
The graph below shows that our time-delayed bottleneck highway network with the DFT input significantly reduces a range of false alarm rates (FAR), yielding approximately a 20 percent relative improvement in the area under the curve (AUC), a common measure of machine-learning model accuracy. It is also clear from our work that a larger amount of training data would improve wake word detection performance.
Monophone-Based Background Modeling
In this paper, we introduce a two-stage on-device wake word detection system based on DNN acoustic modeling, propose a new approach for modeling background noise using monophone-based sound units, and present how richer information can be extracted from the monophone sound units to improve wake word accuracy.

With this new approach, we achieved about a 16 percent relative reduction in instances where Alexa doesn’t respond to the wake word (false rejection rates, or FRR) and about a 37 percent relative reduction in instances when Alexa mistakenly believes she’s heard the wake word, or false alarm rates (FAR). Moreover, when we introduce a second-stage classifier that extracts monophone units for final wake word detection, we reduce FAR by about 67 percent utilizing very few additional computational resources.
Below are the papers we’re presenting at ICASSP next week. Although each method is presented as separate work, both techniques can of course be combined to achieve better wake word performance. That will be the focus of our future work.
Papers:
"Time-Delayed Bottleneck Highway Networks Using A DFT Feature For Keyword Spotting"
"Monophone-based Background Modeling For Two-Stage On-Device Wake Word Detection"
Acknowledgements: Kenichi Kumatani, Sankaran Panchapagesan, Jinxi Guo, Ming Sun, Anirudh Raju, Jiacheng Gu, Ryan Thomas, Nikko Ström, Shiv Naga Prasad Vitaladevuni, Bjorn Hoffmeister, Arindam Mandal, as well as the entire Wake Word team for supporting this work.



